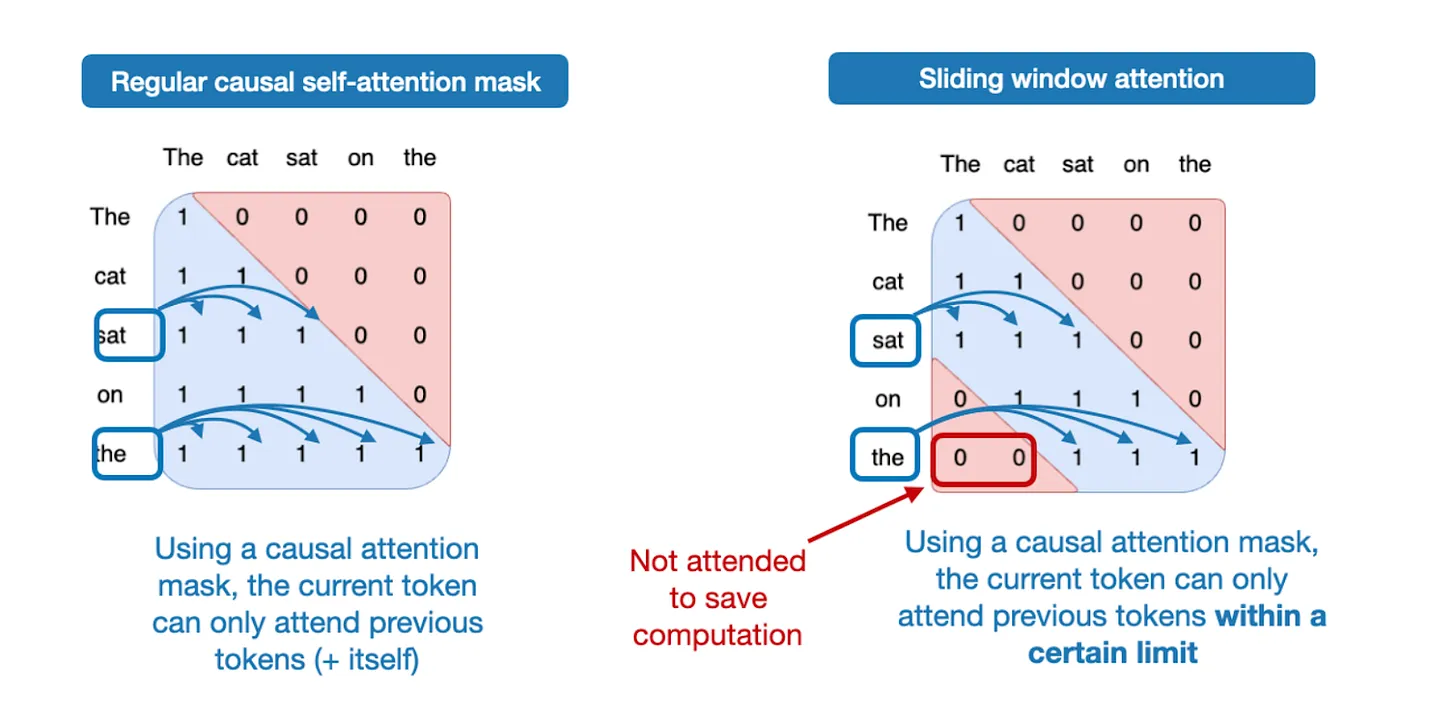
Grouped-Query Attention (GQA)¶
 Comparação MHA (esquerda), GQA (centro) e MQA (direita). Fonte: GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints.
Comparação MHA (esquerda), GQA (centro) e MQA (direita). Fonte: GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints.





Root Mean Square Layer Normalization¶
$\text{RMSNorm}(x) = \gamma \odot \frac{x}{\sqrt{\frac{1}{d} \sum_{i=1}^{d} x_i^2 + \epsilon}}$, onde $\odot$ é a multiplicação elemento-a-elemento.
class RMSNorm(nn.Module):
def __init__(self, normalized_shape: list | tuple,
eps: float = 1e-5, element_affine: bool = True,
):
super().__init__()
self.eps = eps
self.element_affine = element_affine
if self.element_affine:
self.gamma = nn.Parameter(torch.ones(normalized_shape))
else:
self.register_parameter("gamma", None)
def forward(self, x: torch.Tensor):
x = x * torch.rsqrt(self.eps + x.pow(2).mean(dim=-1, keepdim=True))
return x if self.gamma is None else x * self.gamma
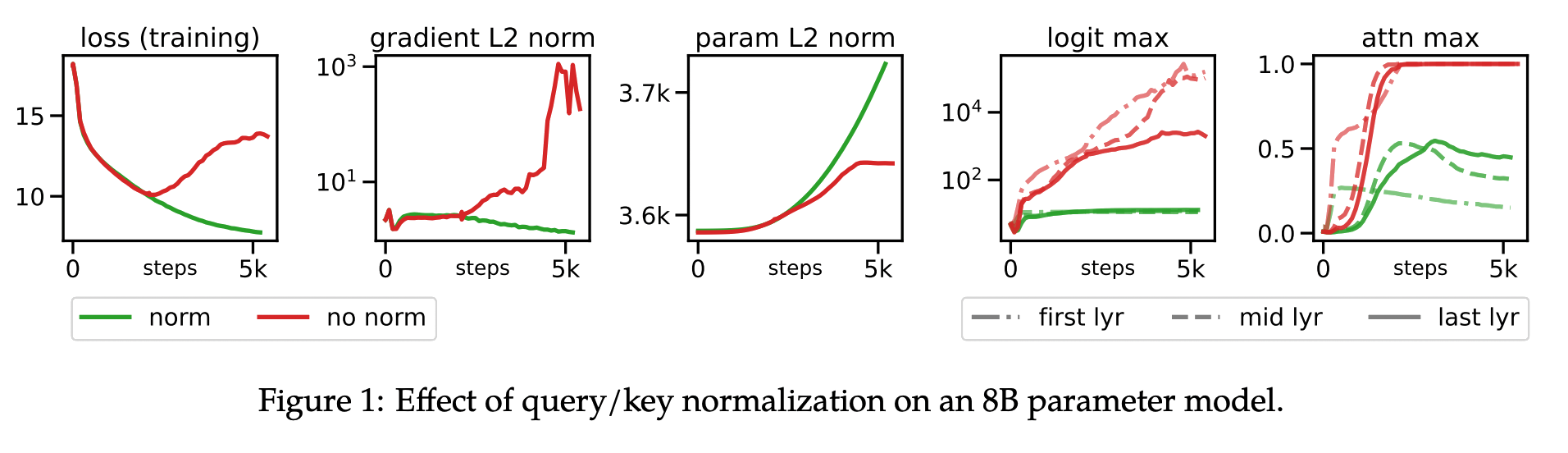
Query-Key Normalization¶
Ideia: Aplicar L2 norm às matrizes Q e K antes do cálculo de atenção.
De: $\text{Attention}(Q,K,V)=\text{softmax}(\frac{QK^T}{\sqrt{d_k}})V$ Para: $\text{QK-Norm}(Q,K,V)=\text{softmax}(\frac{Q}{\Vert Q \Vert_2} \cdot (\frac{K}{\Vert K \Vert_2})^T)V$


Extra: O preço da formatação¶
 Comparação de tokens no tokenizer GPT-4o. Formatação de código no prompt tem seu preço. Fonte: https://arxiv.org/html/2508.13666v1.
Comparação de tokens no tokenizer GPT-4o. Formatação de código no prompt tem seu preço. Fonte: https://arxiv.org/html/2508.13666v1.
"Removing code formatting can substantially reduce input tokens for languages that do not deeply integrate formatting elements into their syntax (e.g., Java, C++, C#) and only slightly reduce tokens for languages like Python, where formatting is essential to syntax and functionality."
Leitura Recomendada¶
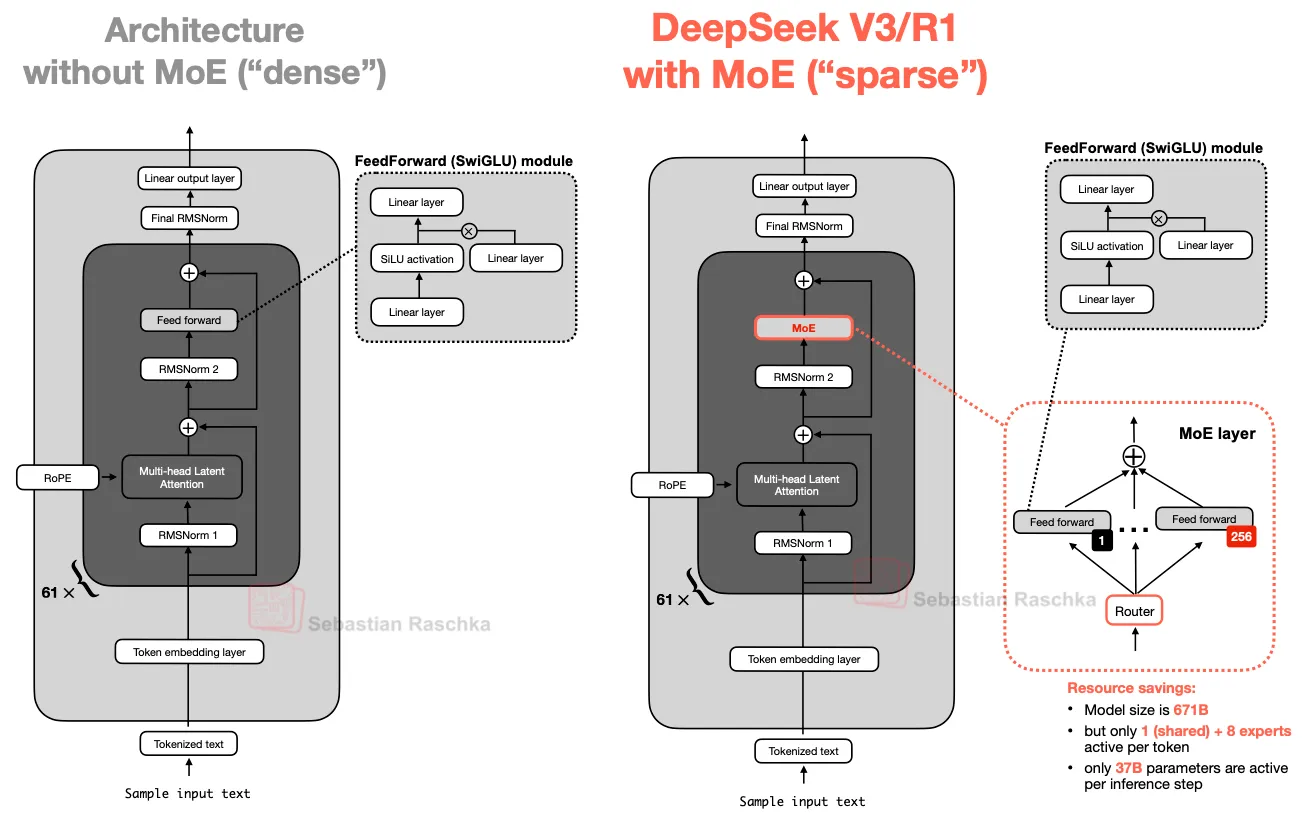
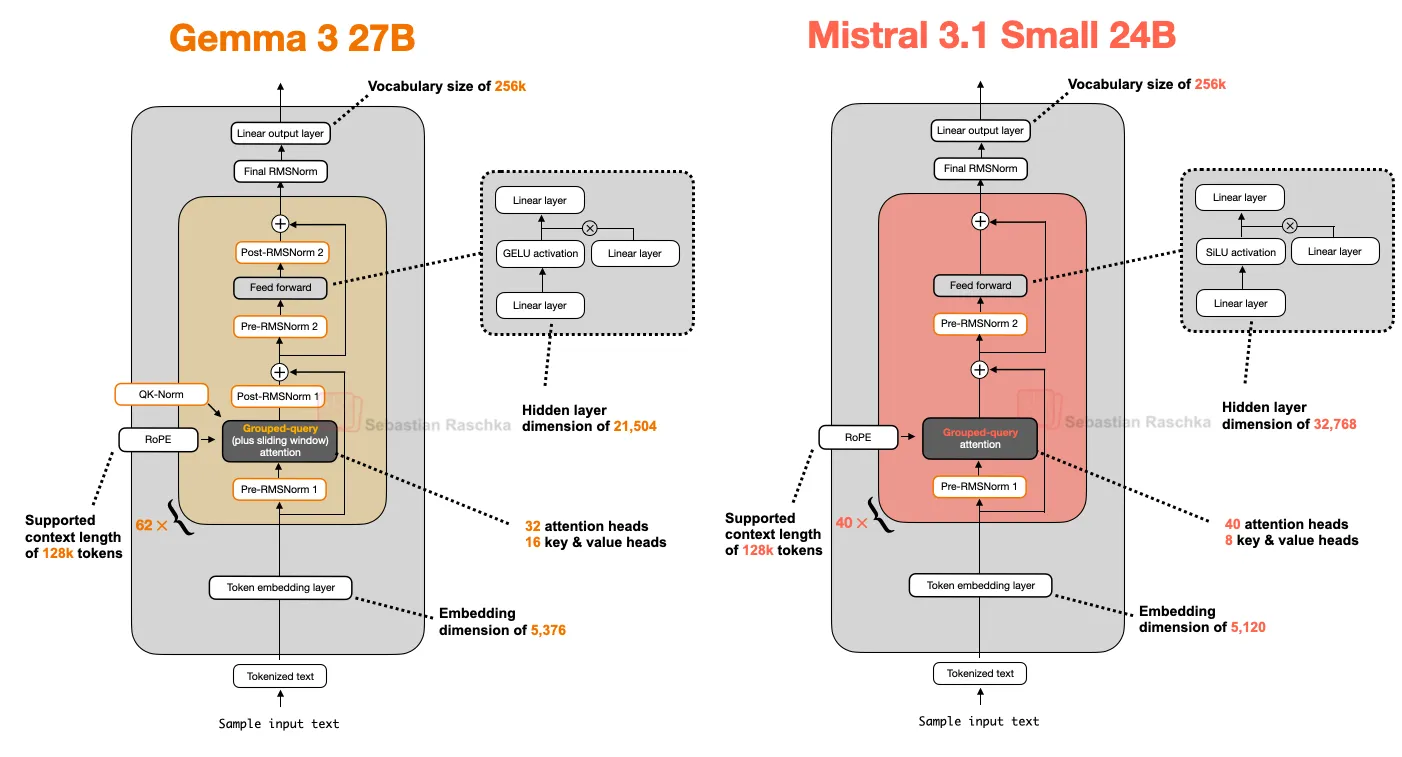
- Sebastian Raschka blog (Ahead of AI): https://magazine.sebastianraschka.com/p/the-big-llm-architecture-comparison
- The Transformer++: https://www.gleech.org/tplus
- Applied LLMs: https://applied-llms.org/
- Eugene Yan blog: https://eugeneyan.com/
- Hugging Face Papers (antigo Papers with Code): https://huggingface.co/papers/trending