Objetivos de Aprendizagem¶
- Explicar a necessidade e função do Ajuste Fino de Instruções (AFI)
- Descrever a metodologia de treinamento e perda: detalhar a estrutura dos dados de AFI (instrução, contexto, resposta alvo) e explicar a função da perda
- Avaliar o desempenho do modelo: utilizar métricas de avaliação e entender o papel de modelos externos (LLM-as-a-Judge) na avaliação da qualidade do alinhamento.
|
Baseado no Livro Build a Large Language Model From Scratch de Sebastian Raschka Code repository: https://github.com/rasbt/LLMs-from-scratch |

|
Relembrando: O Conceito de Fine-Tuning¶
- Definição: É o processo de utilizar um modelo pré-treinado como base e treiná-lo adicionalmente em um dataset menor e específico de um domínio ou tarefa.
- Objetivo: Adaptar o modelo ao novo contexto, aprimorando o desempenho em aplicações especializadas, como tradução de linguagem, análise de sentimento ou sumarização.
- Vantagem: O fine-tuning se baseia no conhecimento pré-existente do modelo, o que reduz substancialmente os requisitos computacionais e de dados em comparação com o treinamento do modelo do zero (pre-training).
Por Que os LLMs Tradicionais Falham com Diretivas¶
- Objetivo do Pré-treinamento: Os LLMs são otimizados para o reconhecimento de padrões linguísticos, minimizando o erro de previsão contextual da próxima palavra em vastos corpora.
- O modelo prevê o próximo token em uma sequência com base em padrões estatísticos.
- A Limitação: Este objetivo de previsão do próximo token não otimiza inerentemente o modelo para seguir instruções explícitas do usuário.
- Sem treinamento adicional, um LLM de base simplesmente completa um prompt, em vez de fornecer uma resposta útil.
- Exemplo: Solicitar "me ensine a fazer pão" pode resultar em "em um forno de casa" (uma conclusão gramaticalmente correta, mas inútil).
- A Solução: O AFI refina o modelo pré-treinado para interpretar as consultas do usuário como instruções formais que exigem ações específicas.
O Que é Ajuste Fino de Instruções (AFI)?¶
- Definição: AFI é uma técnica de ajuste fino que refina LLMs pré-treinados para aderir a instruções de tarefas específicas.
- Metodologia: Envolve treinamento supervisionado em conjuntos de dados que consistem em pares explícitos de prompt-resposta.
- Função Chave: O AFI preenche a lacuna entre a capacidade inerente de previsão da próxima palavra do LLM e o objetivo definido pelo ser humano de aderir a diretivas.
- Benefícios:
- Alinhamento: Conecta o objetivo de pré-treinamento com o objetivo de seguir instruções.
- Controlabilidade: Restringe os outputs do modelo para alinhá-los com as características desejadas (e.g., formato ou conhecimento de domínio).
- Generalização: Modelos ajustados por instruções demonstram forte desempenho zero-shot e few-shot em tarefas não vistas.
Anatomia de uma Amostra de Dados AFI¶
O AFI requer pares de instruções e seus outputs de alta qualidade correspondentes.
- 1. Instrução (A Diretiva): Define claramente a tarefa necessária.
- Exemplo: "Traduza a seguinte frase para o Francês".
- 2. Input/Contexto (O Conteúdo): Informações suplementares opcionais relevantes para a tarefa.
- Exemplo: "A frase a traduzir: 'O processo de ajuste fino é complexo.'".
- 3. Resposta Alvo (A Resposta Ouro): O output de referência de alta qualidade que demonstra a conclusão correta da tarefa.
Estratégias de Coleta de Dados I¶
A curadoria e o dimensionamento de pares de instrução-output de alta qualidade são desafios centrais do AFI.
- 1. Dados Criados por Humanos: Dados anotados manualmente ou obtidos diretamente, confiando apenas na coleta e verificação humana.
- Prós: Geralmente a mais alta qualidade e consistência.
- Contras: Demorado e custoso para grandes escalas.
- Exemplos: Databricks Dolly (15K instâncias, abrangendo 7 tipos como Q&A, escrita criativa), Meta LIMA (1K exemplos cuidadosamente selecionados).
- 2. Integração de Dados de Conjuntos de Dados Anotados:
- Envolve a conversão de conjuntos de dados de PLN existentes (e.g., NLI, análise de sentimentos) em pares de instrução-output usando templates.
- Isto formaliza diversas tarefas de PLN em um formato unificado sequence-to-sequence.
- Exemplos: FLAN (transforma 62 benchmarks de PLN), P3 (integra 170 conjuntos de dados de PLN).
Estratégias de Coleta de Dados II¶
LLMs podem ser usados para aumentar conjuntos de dados de AFI quando a criação manual é inviável.
- Self-Instruct: Começa com um pequeno conjunto de pares sementes. Um LLM gera novas instruções e outra instância gera outputs correspondentes.
- Exemplo: O modelo Alpaca usou 52K pares sintéticos gerados desta forma.
- Bonito: Converte texto não anotado em datasets de treino para AFI. Modelo base: Mistral-7B
- Magpie: Gera dados de instrução solicitando a um LLM alinhado (e.g., Llama 3 8B Instruct) com um template de pré-consulta para sintetizar instruções e respostas de forma totalmente automática.
Alpaca¶
 Workflow Alpaca. AFI sobre o modelo base Llama-7B. Qualidade similar ao modelo da OpenAI, mas muito menor e mais barato de reproduzir. Fonte: Weights and Biases.
Workflow Alpaca. AFI sobre o modelo base Llama-7B. Qualidade similar ao modelo da OpenAI, mas muito menor e mais barato de reproduzir. Fonte: Weights and Biases.
Bonito¶
 Workflow do framework Bonito. Fonte: Learning to Generate Instruction Tuning Datasets for Zero-Shot Task Adaptation.
Workflow do framework Bonito. Fonte: Learning to Generate Instruction Tuning Datasets for Zero-Shot Task Adaptation.
Magpie¶
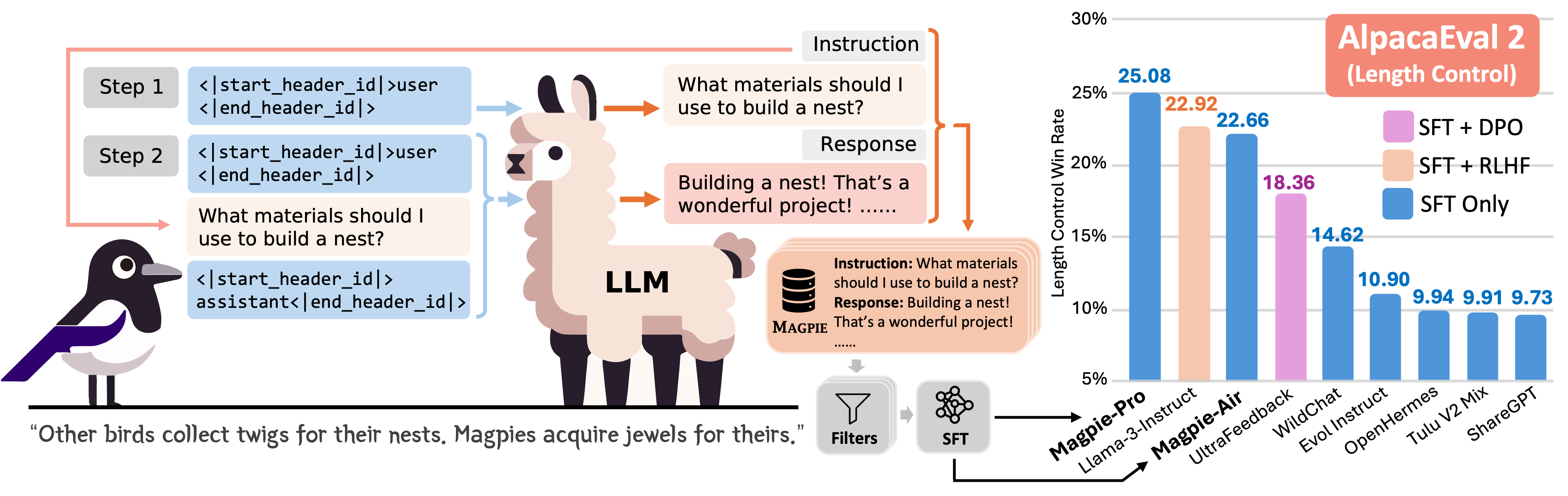 Workflow do framework Magpie. Step 1: apenas pre-query template como entrada para LLM e geração autorregressiva de instrução. Step 2: Combinação de post-query template e outra pre-query template. Fonte: Magpie: Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing.
Workflow do framework Magpie. Step 1: apenas pre-query template como entrada para LLM e geração autorregressiva de instrução. Step 2: Combinação de post-query template e outra pre-query template. Fonte: Magpie: Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing.
Pré-processamento¶
- Formatação do Prompt: Adote um estilo de prompt consistente (e.g., Alpaca) para todas as amostras de treinamento.
- Tokenização: Converta o texto formatado de instrução-resposta em IDs de token.
- Colagem/Preenchimento Customizado (packing): Uma função de colagem customizada é usada para preencher sequências dentro de um lote (ou batch) até o comprimento da sequência mais longa nesse lote.
- Mascaramento de Instrução (Opcional): Mascarar IDs de token que correspondem à instrução impede que a função de perda seja calculada sobre o texto da instrução. Isto força o modelo a focar o treinamento na geração da resposta. Mas... (veja figura ao lado).
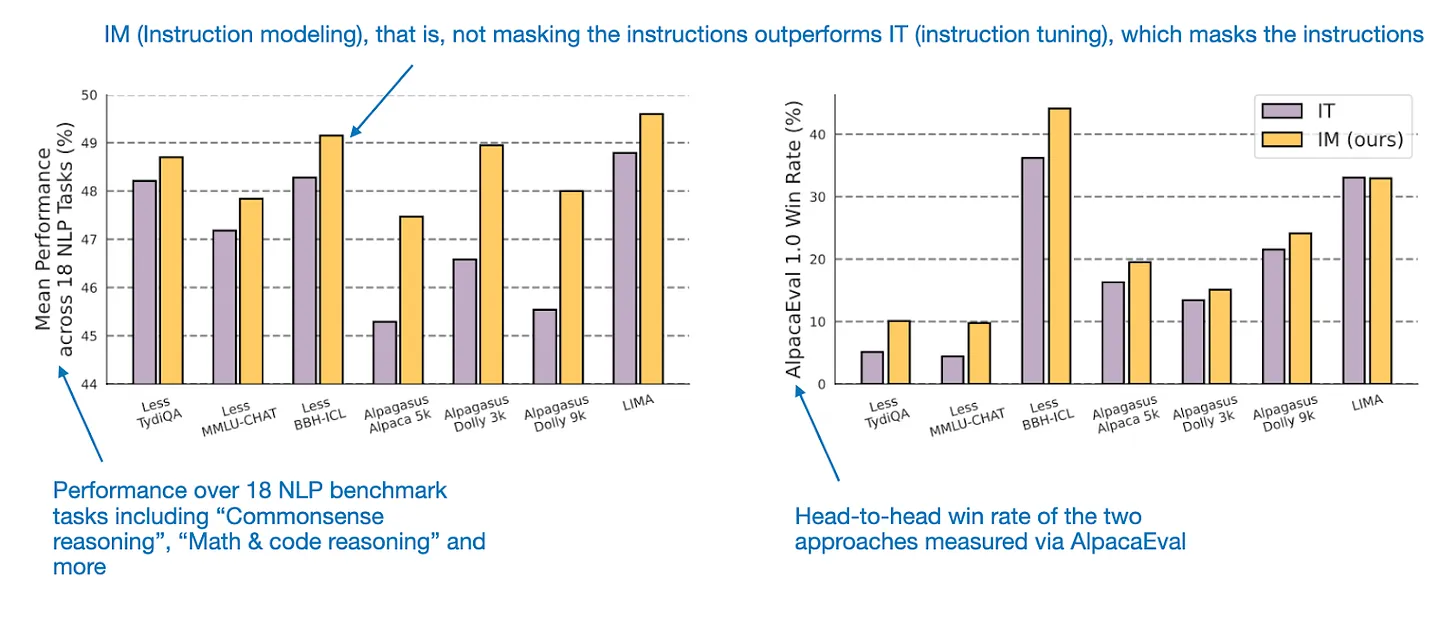 Instruction Masking x Instruction Modeling (não mascara instrução) em (https://arxiv.org/html/2405.14394v2). Fonte: Raschka.
Instruction Masking x Instruction Modeling (não mascara instrução) em (https://arxiv.org/html/2405.14394v2). Fonte: Raschka.
Packing¶
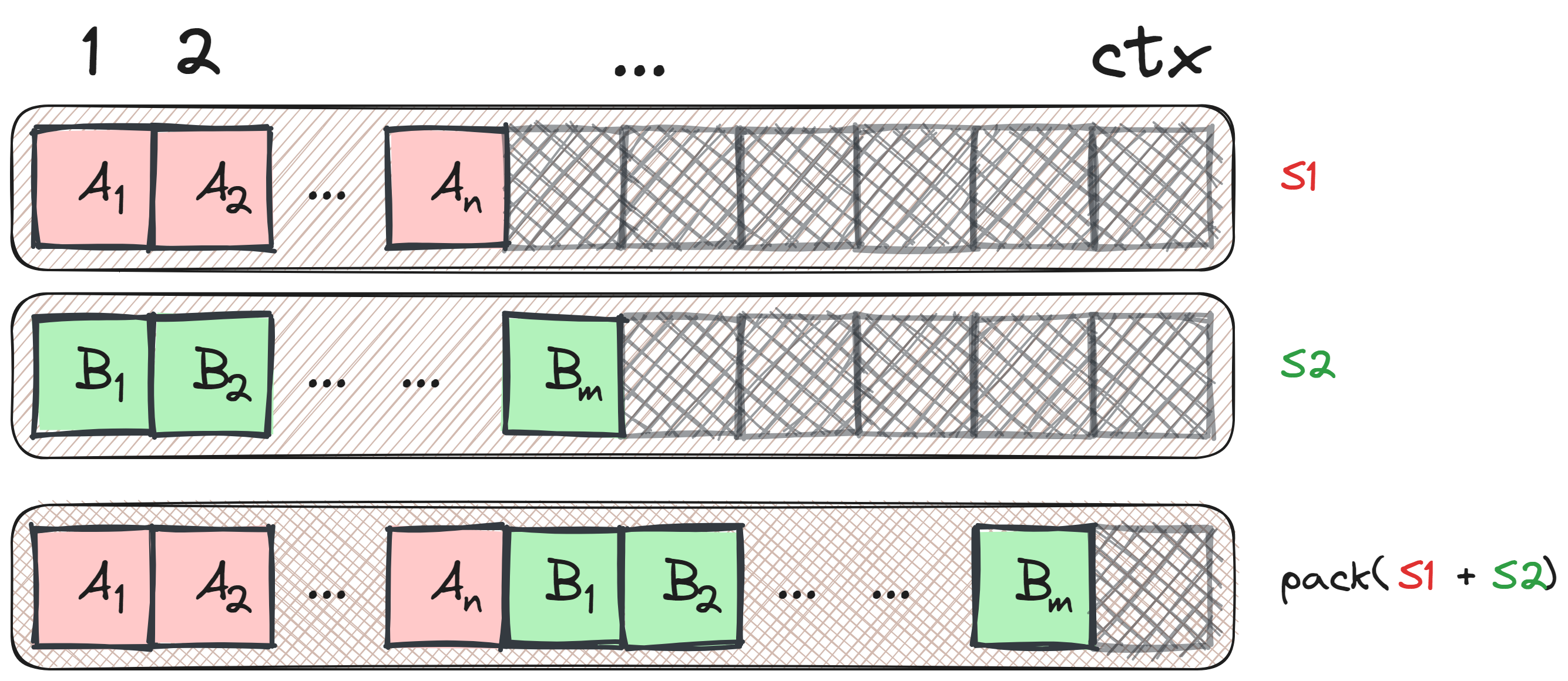 Packing: Combinando múltiplas amostras em uma única sentença. Fonte: Laurens Weitkamp.
Packing: Combinando múltiplas amostras em uma única sentença. Fonte: Laurens Weitkamp.
|
 Packing: Otimização do tamanho do contexto. Fonte: Weights and Biases.
Packing: Otimização do tamanho do contexto. Fonte: Weights and Biases.
|
Eficiência: Ajuste Fino com Eficiência de Parâmetros (PEFT)¶
O Ajuste Fino Completo (Full Fine-Tuning) é caro e corre o risco de esquecimento catastrófico. Os métodos PEFT reduzem drasticamente os custos.
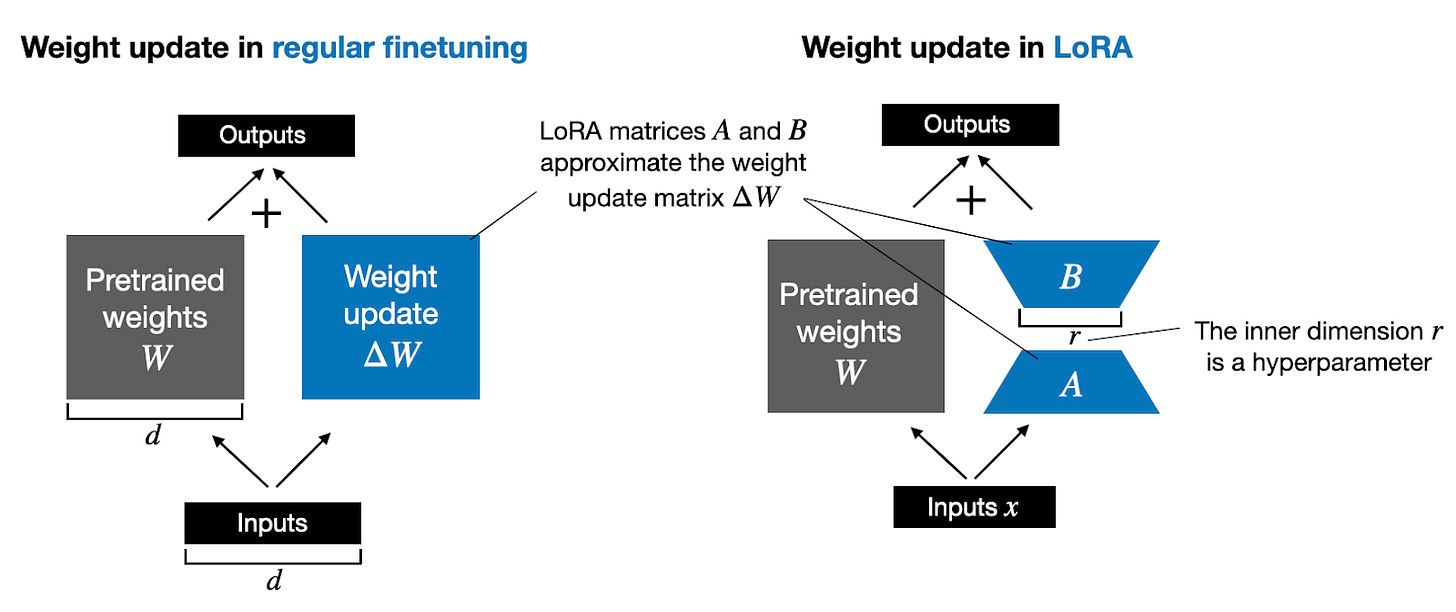
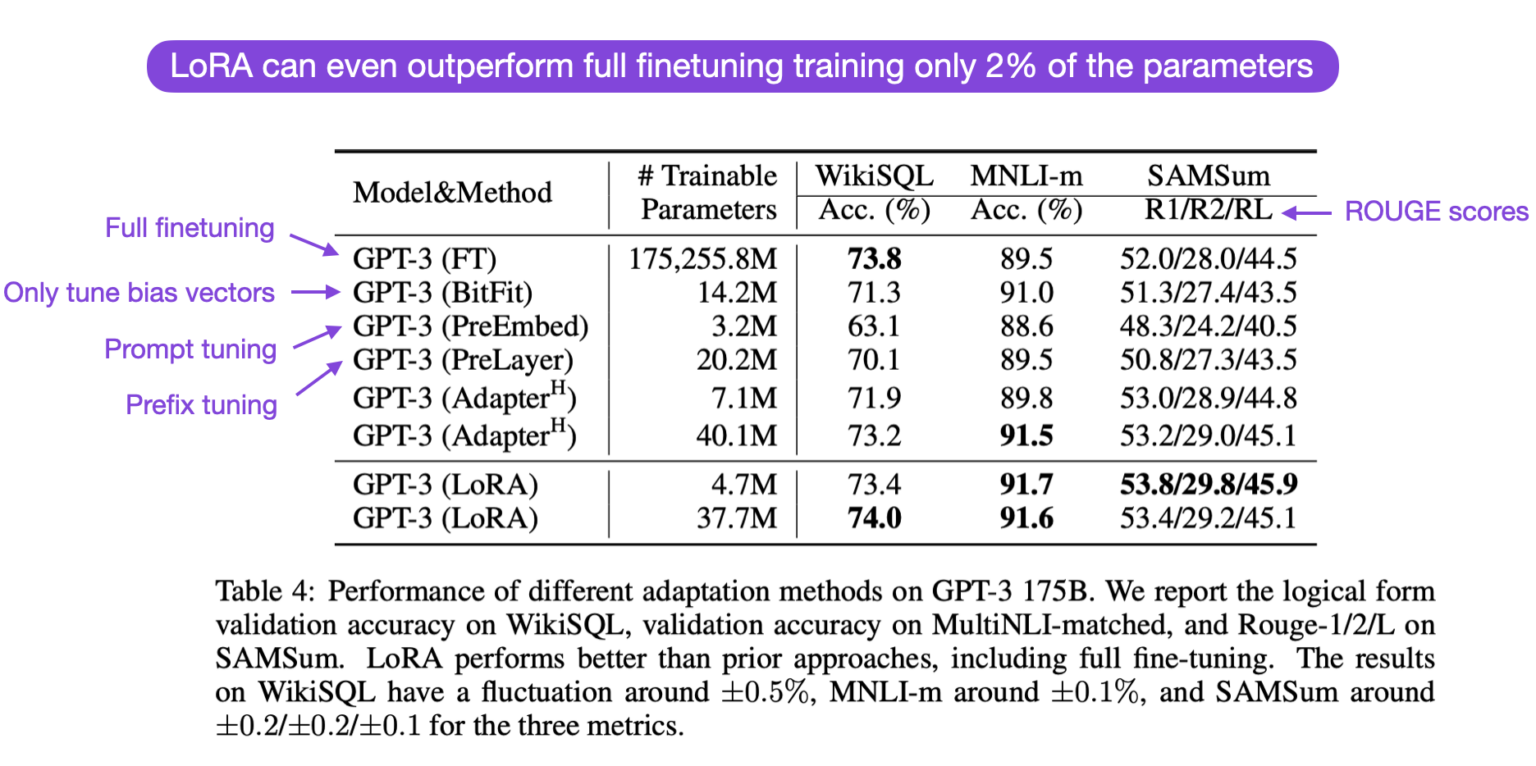
- Low-Rank Adaptation (LoRA): A técnica PEFT mais comum.
- Mantém a maioria dos parâmetros LLM pré-treinados congelados.
- Injeta pequenas matrizes de decomposição de baixa classificação ($A$ e $B$) nos parâmetros de atenção.
- Reduz drasticamente o número de parâmetros treináveis (e.g., 10.000x de redução para GPT-3) e o uso de memória.
- Quantized LoRA (QLoRA): Uma extensão do LoRA otimizando ainda mais a memória.
- Quantiza os pesos base do LLM congelado para precisão ultrabaixa (e.g., 4-bit).
- Permite o ajuste fino de modelos de alta qualidade usando uma única GPU de consumo.
- Veja também o vídeo no Youtube: LoRA explained (and a bit about precision and quantization).
import torch.nn as nn
class LoRALayer(nn.Module):
def __init__(self, in_dim, out_dim, rank, alpha):
super().__init__()
std_dev = 1 / torch.sqrt(torch.tensor(rank).float())
self.A = nn.Parameter(torch.randn(in_dim, rank) * std_dev)
self.B = nn.Parameter(torch.zeros(rank, out_dim))
self.alpha = alpha
def forward(self, x):
x = self.alpha * (x @ self.A @ self.B)
return x
class LinearWithLoRA(nn.Module):
def __init__(self, linear, rank, alpha):
super().__init__()
self.linear = linear
self.lora = LoRALayer(
linear.in_features, linear.out_features, rank, alpha
)
def forward(self, x):
return self.linear(x) + self.lora(x)
Métricas de Avaliação I: Quantitativas e Técnicas¶
A avaliação mede o quão bem o modelo ajustado fino generaliza e adere aos objetivos. Leia mais em Patterns for Building LLM-based Systems & Products.
- Cross-Entropy Loss (Perda de Entropia Cruzada): A métrica fundamental monitorada durante o treinamento e a validação.
- Quantifica a diferença entre a distribuição de probabilidade prevista pelo modelo e a distribuição real de tokens.
- Métricas de PLN Tradicionais (para tarefas específicas):
- BLEU: Mede a proximidade entre traduções geradas e de referência (Tradução Automática, Sumarização).
- Acurácia/F1 Score: Usado para tarefas de classificação e QA.
- Avaliação de Codificação:
- HumanEval: Consiste em 164 problemas de programação para avaliar a capacidade do modelo de gerar programas corretos a partir de docstrings.
- Aderência à Instrução:
- IFEval (Instruction Following Evaluation): Testa especificamente a capacidade de um modelo de seguir restrições explícitas, como contagem de palavras ou formatação de output necessária.
Métricas de Avaliação II: Alinhamento e Pontuação¶
Para geração aberta, as métricas puramente automatizadas geralmente são insuficientes, exigindo avaliação centrada no ser humano.
- LLM-como-Juiz (LLM-as-a-Judge): Utiliza um LLM altamente capaz (e.g., Llama 3 8B) para avaliar a qualidade dos outputs.
- O modelo Juiz recebe o input, o output correto e a resposta do modelo ajustado fino, fornecendo uma pontuação numérica (e.g., 0 a 100).
- Isto é eficiente para avaliação em grande escala.
- Benchmarking de Alinhamento:
- MT-Bench: Usa 80 questões multi-turno de alta qualidade para avaliar o alinhamento com a preferência humana, cobrindo tarefas como escrita, codificação e raciocínio.
- WildBench: Curado a partir de interações reais do usuário, apresentando 1.024 instruções desafiadoras que exigem pensamento crítico.
- Métricas de Segurança: Avaliam respostas do LLM quanto a toxicidade, viés e aderência a diretrizes de segurança. Exemplos incluem Llama Guard 2/3 e ShieldGemma.
Armadilhas Comuns e Limitações em AFI¶
O AFI está sujeito a modos de falha específicos que podem minar a utilidade a longo prazo.
- Esquecimento Catastrófico (Catastrophic Forgetting): O ajuste fino em novas tarefas pode fazer com que o modelo perca o conhecimento pré-treinado.
- Mitigação: Usar técnicas PEFT (LoRA/QLoRA) para congelar a maioria dos pesos base.
- Alinhamento Superficial (Superficial Alignment): O modelo aprende apenas padrões de superfície e estilos (e.g., formato de output ou tom) em vez de melhorar o raciocínio subjacente.
- Isto levanta a preocupação de que os ganhos de desempenho dependam fortemente das tarefas representadas no dado de treinamento.
- Dependência da Qualidade dos Dados: O desempenho depende criticamente da qualidade, diversidade e cobertura de tarefas do conjunto de dados de instrução.
- Dados mal selecionados (especialmente sintéticos) podem reforçar vieses ou deficiências.
Resumo e Leitura Adicional¶
- O AFI (SFT) é essencial para alinhar a previsão do próximo token dos LLMs com os objetivos do usuário.
- O AFI depende de pares de instrução-resposta de alta qualidade e diversificados, gerados manualmente (Flan, Dolly) ou sinteticamente (Self-Instruct, Evol-Instruct).
- O processo de treinamento usa uma perda de objetivo duplo e se beneficia de aprimoramentos arquiteturais (e.g., arquitetura de dois fluxos) e PEFT (LoRA/QLoRA).
- A avaliação requer métricas quantitativas (Entropia Cruzada, HumanEval) e técnicas qualitativas (LLM-como-Juiz, checagens de segurança).
- Leitura Adicional:
1. Preparação de um Conjunto de Dados para Ajuste Fino Supervisionado por Instruções¶
Nesta seção, realizamos o download e a formatação do conjunto de dados de instrução destinado ao ajuste fino (finetuning) supervisionado de um modelo LLM pré‑treinado. O dataset contém 1 100 pares de instruction–response semelhantes aos apresentados anteriormente. Ele foi criado especificamente para este notebook; entretanto, existem outros conjuntos de dados de instruções disponíveis publicamente.
O código a seguir implementa e executa uma função que baixa esse conjunto de dados — um arquivo relativamente pequeno, com apenas 204 KB, em formato JSON. O JSON (JavaScript Object Notation) espelha a estrutura dos dicionários Python, oferecendo uma representação simples e legível por humanos e também adequada para intercâmbio de dados entre máquinas.
import json
import os
import urllib
def download_and_load_file(file_path, url):
if not os.path.exists(file_path):
with urllib.request.urlopen(url) as response:
text_data = response.read().decode("utf-8")
with open(file_path, "w", encoding="utf-8") as file:
file.write(text_data)
else: # Skip download if file was already downloaded
with open(file_path, "r", encoding="utf-8") as file:
text_data = file.read()
with open(file_path, "r", encoding="utf-8") as file:
data = json.load(file)
return data
file_path = "instruction-data.json" # prepared by Sebastian Raschka (in Alpaca format)
url = (
"https://raw.githubusercontent.com/rasbt/LLMs-from-scratch"
"/main/ch07/01_main-chapter-code/instruction-data.json"
)
data = download_and_load_file(file_path, url)
print("Number of entries:", len(data))
Number of entries: 1100
print("Example entry:\n", data[50])
Example entry:
{'instruction': 'Identify the correct spelling of the following word.', 'input': 'Ocassion', 'output': "The correct spelling is 'Occasion.'"}
print("Another example entry:\n", data[999])
Another example entry:
{'instruction': "What is an antonym of 'complicated'?", 'input': '', 'output': "An antonym of 'complicated' is 'simple'."}
Ajuste fino por instruções costuma ser chamado de “supervised instruction finetuning” porque envolve treinar um modelo em um conjunto de dados no qual os pares entrada‑saída são explicitamente fornecidos. Existem diferentes formas de formatar as entradas como input para o LLM; a figura abaixo ilustra dois formatos utilizados, respectivamente, nos modelos Alpaca (https://crfm.stanford.edu/2023/03/13/alpaca.html) e Phi‑3 (https://arxiv.org/abs/2404.14219):
O estilo Alpaca (esquerda) emprega um formato estruturado com seções definidas para instrução, input e resposta;
O estilo Phi‑3 (direita) utiliza um formato mais simples com tokens designados <|user|> e <|assistant|>.
Utilizamos a formatação de prompt no estilo Alpaca, que foi o template original para ajuste fino por instruções. A seguir, formatamos a entrada que será enviada ao LLM.
def format_input(entry):
instruction_text = (
f"Below is an instruction that describes a task. "
f"Write a response that appropriately completes the request."
f"\n\n### Instruction:\n{entry['instruction']}"
)
input_text = f"\n\n### Input:\n{entry['input']}" if entry["input"] else ""
return instruction_text + input_text
model_input = format_input(data[50])
desired_response = f"\n\n### Response:\n{data[50]['output']}"
print(model_input + desired_response)
Below is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: Identify the correct spelling of the following word. ### Input: Ocassion ### Response: The correct spelling is 'Occasion.'
model_input = format_input(data[999])
desired_response = f"\n\n### Response:\n{data[999]['output']}"
print(model_input + desired_response)
Below is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: What is an antonym of 'complicated'? ### Response: An antonym of 'complicated' is 'simple'.
train_portion = int(len(data) * 0.85) # 85% for training
test_portion = int(len(data) * 0.1) # 10% for testing
val_portion = len(data) - train_portion - test_portion # Remaining 5% for validation
train_data = data[:train_portion]
test_data = data[train_portion:train_portion + test_portion]
val_data = data[train_portion + test_portion:]
print("Training set length:", len(train_data))
print("Validation set length:", len(val_data))
print("Test set length:", len(test_data))
Training set length: 935 Validation set length: 55 Test set length: 110
2. Organização dos Dados em Batches de Treino¶
Ao avançarmos na fase de implementação do processo de ajuste fino supervisionado por instruções, o próximo passo concentra-se na construção eficiente dos batches de treino. Isto requer definir um método que assegure que o modelo receba os dados formatados adequadamente durante o fine‑tuning.
Em ajuste fino para classificação, os batches eram gerados automaticamente pela classe DataLoader do PyTorch, a qual utiliza uma função collate padrão para combinar listas de amostras em batches. A função collate é responsável por receber uma lista de dados individuais e consolidá‑la num único batch que pode ser processado eficientemente pelo modelo.
Para ajuste fino supervisionado por instruções, o processo de batching envolve etapas adicionais: precisamos criar nossa própria função collate customizada, que será posteriormente inserida no DataLoader. Implementaremos essa função para atender às exigências específicas e à formatação do nosso conjunto de dados de instruções.
Dividimos a implementação do batching em cinco passos (conforme ilustrado na figura abaixo):
Primeiro, implementamos a classe InstructionDataset, que pré‑tokeniza todas as entradas do dataset — de forma análoga à SpamDataset usada em classificação — passando do formato JSON ao texto e, daí, aos IDs dos tokens. Este processo de dois passos ocorre no construtor __init__.
import torch
from torch.utils.data import Dataset
class InstructionDataset(Dataset):
def __init__(self, data, tokenizer):
self.data = data
# Pre-tokenize texts
self.encoded_texts = []
for entry in data:
instruction_plus_input = format_input(entry)
response_text = f"\n\n### Response:\n{entry['output']}"
full_text = instruction_plus_input + response_text
self.encoded_texts.append(
tokenizer.encode(full_text)
)
def __getitem__(self, index):
return self.encoded_texts[index]
def __len__(self):
return len(self.data)
Aqui, nós coletamos múltiplos exemplos de treinamento em um só batch para acelerar o treinamento. Isso requer padding em todas as entradas para gerar tamanhos similares e adicionar <|endoftext|> como token de padding.
import tiktoken
tokenizer = tiktoken.get_encoding("gpt2")
print(tokenizer.encode("<|endoftext|>", allowed_special={"<|endoftext|>"}))
[50256]
Em ajuste fino por classificação, todos os exemplos eram padronizados para o mesmo comprimento globalmente. Aqui adotamos uma abordagem mais refinada: criamos uma função collate customizada que recebe cada batch individualmente e adiciona padding apenas até a maior sequência presente naquele batch (não em todo o dataset). Isto minimiza o padding desnecessário, pois batches diferentes podem ter comprimentos distintos.
A figura abaixo demonstra como os exemplos de treino são padronizados dentro de um batch usando o token ID 50256 para garantir comprimento uniforme. Cada batch pode ter tamanho diferente, como ilustrado nos dois primeiros batches da figura.
Podemos implementar esse processo de padding com a função collate customizada que operará sobre cada batch (a collate cuidará das etapas 2.3 a 2.5; a implementação será feita em vários rascunhos):
def custom_collate_draft_1( # just taking care of step 2.3
batch,
pad_token_id=50256,
device="cpu"
):
# Find the longest sequence in the batch and increase the max length by +1, which will add one extra
# padding token below
batch_max_length = max(len(item)+1 for item in batch)
# Pad and prepare inputs
inputs_lst = []
for item in batch:
new_item = item.copy()
# Add an <|endoftext|> token
new_item += [pad_token_id]
# Pad sequences to batch_max_length
padded = (
new_item + [pad_token_id] *
(batch_max_length - len(new_item))
)
# Via padded[:-1], we remove the extra padded token
# that has been added via the +1 setting in batch_max_length
# (the extra padding token will be relevant in later codes)
inputs = torch.tensor(padded[:-1])
inputs_lst.append(inputs)
# Convert list of inputs to tensor and transfer to target device
inputs_tensor = torch.stack(inputs_lst).to(device)
return inputs_tensor
Esta função será posteriormente passada ao DataLoader para gerar batches adequados ao ajuste fino supervisionado por instruções.
inputs_1 = [0, 1, 2, 3, 4]
inputs_2 = [5, 6]
inputs_3 = [7, 8, 9]
batch = (
inputs_1,
inputs_2,
inputs_3
)
print(custom_collate_draft_1(batch))
tensor([[ 0, 1, 2, 3, 4],
[ 5, 6, 50256, 50256, 50256],
[ 7, 8, 9, 50256, 50256]])
Esta figura ilustra o alinhamento entre os tokens de entrada e os tokens alvo utilizados no processo de ajuste fino por instruções de um LLM.
def custom_collate_draft_2(
batch,
pad_token_id=50256,
device="cpu"
):
# Find the longest sequence in the batch
batch_max_length = max(len(item)+1 for item in batch)
# Pad and prepare inputs
inputs_lst, targets_lst = [], []
for item in batch:
new_item = item.copy()
# Add an <|endoftext|> token
new_item += [pad_token_id]
# Pad sequences to max_length
padded = (
new_item + [pad_token_id] *
(batch_max_length - len(new_item))
)
inputs = torch.tensor(padded[:-1]) # Truncate the last token for inputs
targets = torch.tensor(padded[1:]) # Shift +1 to the right for targets
inputs_lst.append(inputs)
targets_lst.append(targets)
# Convert list of inputs to tensor and transfer to target device
inputs_tensor = torch.stack(inputs_lst).to(device)
targets_tensor = torch.stack(targets_lst).to(device)
return inputs_tensor, targets_tensor
inputs, targets = custom_collate_draft_2(batch)
print(inputs)
print(targets)
tensor([[ 0, 1, 2, 3, 4],
[ 5, 6, 50256, 50256, 50256],
[ 7, 8, 9, 50256, 50256]])
tensor([[ 1, 2, 3, 4, 50256],
[ 6, 50256, 50256, 50256, 50256],
[ 8, 9, 50256, 50256, 50256]])
No passo seguinte, atribuímos ao valor placeholder –100 a todos os tokens de padding, conforme ilustrado abaixo. Esse valor especial permite que excluamos esses tokens de padding do cálculo da perda de treinamento, garantindo que apenas dados significativos influenciem o aprendizado do modelo.
Depois de criar a sequência alvo deslocando os IDs dos tokens uma posição para a direita e acrescentando um token de fim‑de‑texto, o passo 2.5 concentra‑se em substituir os tokens de padding de fim‑de‑texto por um valor placeholder (–100). Observe que mantemos um token de fim‑de‑texto (ID 50256) na lista alvo. Isso permite que o LLM aprenda quando gerar um token de fim‑de‑texto em resposta às instruções, o qual usamos como indicativo de que a resposta gerada está completa. Concretamente, isso significa substituir os IDs dos tokens correspondentes a 50256 por –100, conforme ilustrado acima.
A figura mostra a substituição de todas as ocorrências do token de fim‑de‑texto, exceto a primeira (que usamos como padding), pelo valor placeholder –100, mantendo o token inicial de fim‑de‑texto em cada sequência alvo.
No trecho de código abaixo, modificamos nossa função de collate personalizada para substituir os tokens com ID 50256 por –100 nas listas de destino. Além disso, introduzimos o parâmetro allowed_max_length que permite limitar opcionalmente o tamanho das amostras. Essa alteração será útil caso você planeje trabalhar com seus próprios conjuntos de dados que excedam o limite de 1 024 tokens suportado pelo modelo GPT‑2. O código da função collate atualizada fica assim:
def custom_collate_fn(
batch,
pad_token_id=50256,
ignore_index=-100, # a default value that cross-entropy loss will ignore
allowed_max_length=None, # truncate in case we have inputs exceeding the context length that the model supports
device="cpu"
):
# Find the longest sequence in the batch
batch_max_length = max(len(item)+1 for item in batch)
# Pad and prepare inputs and targets
inputs_lst, targets_lst = [], []
for item in batch:
new_item = item.copy()
# Add an <|endoftext|> token
new_item += [pad_token_id]
# Pad sequences to max_length
padded = (
new_item + [pad_token_id] *
(batch_max_length - len(new_item))
)
inputs = torch.tensor(padded[:-1]) # Truncate the last token for inputs
targets = torch.tensor(padded[1:]) # Shift +1 to the right for targets
# New: Replace all but the first padding tokens in targets by ignore_index
mask = targets == pad_token_id
indices = torch.nonzero(mask).squeeze()
if indices.numel() > 1:
targets[indices[1:]] = ignore_index # insert -100
# New: Optionally truncate to maximum sequence length
if allowed_max_length is not None:
inputs = inputs[:allowed_max_length]
targets = targets[:allowed_max_length]
inputs_lst.append(inputs)
targets_lst.append(targets)
# Convert list of inputs and targets to tensors and transfer to target device
inputs_tensor = torch.stack(inputs_lst).to(device)
targets_tensor = torch.stack(targets_lst).to(device)
return inputs_tensor, targets_tensor
inputs, targets = custom_collate_fn(batch)
print(inputs)
print(targets)
tensor([[ 0, 1, 2, 3, 4],
[ 5, 6, 50256, 50256, 50256],
[ 7, 8, 9, 50256, 50256]])
tensor([[ 1, 2, 3, 4, 50256],
[ 6, 50256, -100, -100, -100],
[ 8, 9, 50256, -100, -100]])
O primeiro tensor representa as inputs e o segundo representa os targets.
Para testar, vamos ver como a troca para -100 ocorre. Vamos assumir uma pequena tarefa de classificação com 2 classes (0 e 1):
logits_1 = torch.tensor(
[[-1.0, 1.0], # 1st training example
[-0.5, 1.5]] # 2nd training example
)
targets_1 = torch.tensor([0, 1])
loss_1 = torch.nn.functional.cross_entropy(logits_1, targets_1)
print(loss_1)
tensor(1.1269)
Agora, se adicionarmos mais um exemplo de treino, a loss será influenciada:
logits_2 = torch.tensor(
[[-1.0, 1.0],
[-0.5, 1.5],
[-0.5, 1.5]] # New 3rd training example
)
targets_2 = torch.tensor([0, 1, 1])
loss_2 = torch.nn.functional.cross_entropy(logits_2, targets_2)
print(loss_2)
tensor(0.7936)
Vamos ver o que acontece se trocarmos o label da class pro um dos exemplos com -100:
targets_3 = torch.tensor([0, 1, -100])
loss_3 = torch.nn.functional.cross_entropy(logits_2, targets_3)
print(loss_3)
print("loss_1 == loss_3:", loss_1 == loss_3)
tensor(1.1269) loss_1 == loss_3: tensor(True)
O cálculo da loss ignorou o exemplo com label -100. Por padrão, o PyTorch possui a configuração cross_entropy(..., ignore_index=-100) que ignora exemplos correspondentes ao rótulo –100. Usando esse índice de ignorar –100, podemos descartar os tokens adicionais de fim‑de‑texto (padding) nos batches que usamos para padronizar os exemplos de treino a um mesmo comprimento. No entanto, desejamos manter um ID 50256 (fim‑de‑texto) nas metas porque isso ajuda o LLM a aprender a gerar tokens de fim‑de‑texto, os quais podemos usar como sinal de que uma resposta está completa.
3. Criando Data Loaders para um Dataset de Instruções¶
Até agora percorremos diversas etapas para implementar a classe InstructionDataset e a função custom_collate_fn para o dataset de instruções. Nesta seção, podemos colher os frutos do nosso trabalho simplesmente conectando ambos os objetos InstructionDataset e a função custom_collate_fn aos loaders de dados do PyTorch. Esses loaders irão embaralhar e organizar automaticamente os lotes (batches) para o processo de fine‑tuning de instruções no LLM.
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
#if torch.cuda.is_available():
# device = torch.device("cuda")
#elif torch.backends.mps.is_available():
# device = torch.device("mps")
#else:
# device = torch.device("cpu")
print("Device:", device)
Device: cpu
Um detalhe da função custom_collate_fn anterior é que agora movemos os dados diretamente para o dispositivo alvo (por exemplo, GPU), em vez de fazê‑lo dentro do loop principal de treinamento. Isso aumenta a eficiência porque pode ser executado como um processo em segundo plano quando usamos custom_collate_fn como parte do data loader.
Usando a função partial da biblioteca padrão functools do Python, criamos uma nova função com o argumento device pré‑preenchido. O código abaixo inicializa a variável de dispositivo:
from functools import partial
customized_collate_fn = partial(
custom_collate_fn,
device=device,
allowed_max_length=1024
)
from torch.utils.data import DataLoader
num_workers = 0
batch_size = 8
torch.manual_seed(123)
train_dataset = InstructionDataset(train_data, tokenizer)
train_loader = DataLoader(
train_dataset,
batch_size=batch_size,
collate_fn=customized_collate_fn, # here we plug in our customized version
shuffle=True,
drop_last=True,
num_workers=num_workers
)
val_dataset = InstructionDataset(val_data, tokenizer)
val_loader = DataLoader(
val_dataset,
batch_size=batch_size,
collate_fn=customized_collate_fn,
shuffle=False,
drop_last=False,
num_workers=num_workers
)
test_dataset = InstructionDataset(test_data, tokenizer)
test_loader = DataLoader(
test_dataset,
batch_size=batch_size,
collate_fn=customized_collate_fn,
shuffle=False,
drop_last=False,
num_workers=num_workers
)
Vamos verificar as dimensões de inputs e targets gerados pelo dataloader de treino:
print("Train loader:")
for inputs, targets in train_loader:
print(inputs.shape, targets.shape)
Train loader: torch.Size([8, 61]) torch.Size([8, 61]) torch.Size([8, 76]) torch.Size([8, 76]) torch.Size([8, 73]) torch.Size([8, 73]) torch.Size([8, 68]) torch.Size([8, 68]) torch.Size([8, 65]) torch.Size([8, 65]) torch.Size([8, 72]) torch.Size([8, 72]) torch.Size([8, 80]) torch.Size([8, 80]) torch.Size([8, 67]) torch.Size([8, 67]) torch.Size([8, 62]) torch.Size([8, 62]) torch.Size([8, 75]) torch.Size([8, 75]) torch.Size([8, 62]) torch.Size([8, 62]) torch.Size([8, 68]) torch.Size([8, 68]) torch.Size([8, 67]) torch.Size([8, 67]) torch.Size([8, 77]) torch.Size([8, 77]) torch.Size([8, 69]) torch.Size([8, 69]) torch.Size([8, 79]) torch.Size([8, 79]) torch.Size([8, 71]) torch.Size([8, 71]) torch.Size([8, 66]) torch.Size([8, 66]) torch.Size([8, 83]) torch.Size([8, 83]) torch.Size([8, 68]) torch.Size([8, 68]) torch.Size([8, 80]) torch.Size([8, 80]) torch.Size([8, 71]) torch.Size([8, 71]) torch.Size([8, 69]) torch.Size([8, 69]) torch.Size([8, 65]) torch.Size([8, 65]) torch.Size([8, 68]) torch.Size([8, 68]) torch.Size([8, 60]) torch.Size([8, 60]) torch.Size([8, 59]) torch.Size([8, 59]) torch.Size([8, 69]) torch.Size([8, 69]) torch.Size([8, 63]) torch.Size([8, 63]) torch.Size([8, 65]) torch.Size([8, 65]) torch.Size([8, 76]) torch.Size([8, 76]) torch.Size([8, 66]) torch.Size([8, 66]) torch.Size([8, 71]) torch.Size([8, 71]) torch.Size([8, 91]) torch.Size([8, 91]) torch.Size([8, 65]) torch.Size([8, 65]) torch.Size([8, 64]) torch.Size([8, 64]) torch.Size([8, 67]) torch.Size([8, 67]) torch.Size([8, 66]) torch.Size([8, 66]) torch.Size([8, 64]) torch.Size([8, 64]) torch.Size([8, 65]) torch.Size([8, 65]) torch.Size([8, 75]) torch.Size([8, 75]) torch.Size([8, 89]) torch.Size([8, 89]) torch.Size([8, 59]) torch.Size([8, 59]) torch.Size([8, 88]) torch.Size([8, 88]) torch.Size([8, 83]) torch.Size([8, 83]) torch.Size([8, 83]) torch.Size([8, 83]) torch.Size([8, 70]) torch.Size([8, 70]) torch.Size([8, 65]) torch.Size([8, 65]) torch.Size([8, 74]) torch.Size([8, 74]) torch.Size([8, 76]) torch.Size([8, 76]) torch.Size([8, 67]) torch.Size([8, 67]) torch.Size([8, 75]) torch.Size([8, 75]) torch.Size([8, 83]) torch.Size([8, 83]) torch.Size([8, 69]) torch.Size([8, 69]) torch.Size([8, 67]) torch.Size([8, 67]) torch.Size([8, 60]) torch.Size([8, 60]) torch.Size([8, 60]) torch.Size([8, 60]) torch.Size([8, 66]) torch.Size([8, 66]) torch.Size([8, 80]) torch.Size([8, 80]) torch.Size([8, 71]) torch.Size([8, 71]) torch.Size([8, 61]) torch.Size([8, 61]) torch.Size([8, 58]) torch.Size([8, 58]) torch.Size([8, 71]) torch.Size([8, 71]) torch.Size([8, 67]) torch.Size([8, 67]) torch.Size([8, 68]) torch.Size([8, 68]) torch.Size([8, 63]) torch.Size([8, 63]) torch.Size([8, 87]) torch.Size([8, 87]) torch.Size([8, 68]) torch.Size([8, 68]) torch.Size([8, 64]) torch.Size([8, 64]) torch.Size([8, 68]) torch.Size([8, 68]) torch.Size([8, 71]) torch.Size([8, 71]) torch.Size([8, 68]) torch.Size([8, 68]) torch.Size([8, 71]) torch.Size([8, 71]) torch.Size([8, 61]) torch.Size([8, 61]) torch.Size([8, 65]) torch.Size([8, 65]) torch.Size([8, 67]) torch.Size([8, 67]) torch.Size([8, 65]) torch.Size([8, 65]) torch.Size([8, 64]) torch.Size([8, 64]) torch.Size([8, 60]) torch.Size([8, 60]) torch.Size([8, 72]) torch.Size([8, 72]) torch.Size([8, 64]) torch.Size([8, 64]) torch.Size([8, 70]) torch.Size([8, 70]) torch.Size([8, 57]) torch.Size([8, 57]) torch.Size([8, 72]) torch.Size([8, 72]) torch.Size([8, 64]) torch.Size([8, 64]) torch.Size([8, 68]) torch.Size([8, 68]) torch.Size([8, 62]) torch.Size([8, 62]) torch.Size([8, 74]) torch.Size([8, 74]) torch.Size([8, 80]) torch.Size([8, 80]) torch.Size([8, 68]) torch.Size([8, 68]) torch.Size([8, 70]) torch.Size([8, 70]) torch.Size([8, 91]) torch.Size([8, 91]) torch.Size([8, 61]) torch.Size([8, 61]) torch.Size([8, 66]) torch.Size([8, 66]) torch.Size([8, 80]) torch.Size([8, 80]) torch.Size([8, 81]) torch.Size([8, 81]) torch.Size([8, 74]) torch.Size([8, 74]) torch.Size([8, 82]) torch.Size([8, 82]) torch.Size([8, 63]) torch.Size([8, 63]) torch.Size([8, 83]) torch.Size([8, 83]) torch.Size([8, 68]) torch.Size([8, 68]) torch.Size([8, 67]) torch.Size([8, 67]) torch.Size([8, 77]) torch.Size([8, 77]) torch.Size([8, 91]) torch.Size([8, 91]) torch.Size([8, 64]) torch.Size([8, 64]) torch.Size([8, 61]) torch.Size([8, 61]) torch.Size([8, 75]) torch.Size([8, 75]) torch.Size([8, 64]) torch.Size([8, 64]) torch.Size([8, 66]) torch.Size([8, 66]) torch.Size([8, 78]) torch.Size([8, 78]) torch.Size([8, 66]) torch.Size([8, 66]) torch.Size([8, 64]) torch.Size([8, 64]) torch.Size([8, 83]) torch.Size([8, 83]) torch.Size([8, 66]) torch.Size([8, 66]) torch.Size([8, 74]) torch.Size([8, 74]) torch.Size([8, 69]) torch.Size([8, 69])
Na saída, podemos observar que o primeiro lote de entrada e alvo possui dimensões de 8×61, onde 8 representa o tamanho do lote (batch size) e 61 é o número de tokens em cada exemplo de treinamento neste lote. O segundo lote de entrada e alvo possui um número diferente de tokens, por exemplo, 76. Todos os lotes possuem um tamanho de lote de 8, mas um comprimento diferente, como esperado.
Graças à nossa função collate personalizada, o data loader é capaz de criar lotes de comprimentos diferentes. Na próxima seção, carregaremos um LLM pré-treinado que poderemos então ajustar (finetune) com este data loader.
Vamos também verificar se as entradas contêm os tokens de preenchimento <|endoftext|> correspondentes ao ID do token 50256, imprimindo o conteúdo do primeiro exemplo de treinamento no último lote inputs:
print(inputs[0])
tensor([21106, 318, 281, 12064, 326, 8477, 257, 4876, 13, 19430,
257, 2882, 326, 20431, 32543, 262, 2581, 13, 198, 198,
21017, 46486, 25, 198, 30003, 6525, 262, 6827, 1262, 257,
985, 576, 13, 198, 198, 21017, 23412, 25, 198, 464,
5156, 318, 845, 13779, 13, 198, 198, 21017, 18261, 25,
198, 464, 5156, 318, 355, 13779, 355, 257, 4936, 13,
50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256])
Verificamos se os targets incluem -100:
print(targets[0])
tensor([ 318, 281, 12064, 326, 8477, 257, 4876, 13, 19430, 257,
2882, 326, 20431, 32543, 262, 2581, 13, 198, 198, 21017,
46486, 25, 198, 30003, 6525, 262, 6827, 1262, 257, 985,
576, 13, 198, 198, 21017, 23412, 25, 198, 464, 5156,
318, 845, 13779, 13, 198, 198, 21017, 18261, 25, 198,
464, 5156, 318, 355, 13779, 355, 257, 4936, 13, 50256,
-100, -100, -100, -100, -100, -100, -100, -100, -100])
4. Carregando um LLM Pré-treinado¶
Acima, dedicamos muito tempo preparando o conjunto de dados para o ajuste fino (finetuning) por instrução, que é um aspecto fundamental do processo de ajuste supervisionado. Muitos outros aspectos são os mesmos que no pré-treinamento, permitindo-nos reutilizar grande parte do código de episódios anteriores. Especificamente, carregamos um modelo GPT pré-treinado usando o mesmo código de episódios anteriores, que serve como base para o treinamento subsequente. Este modelo pré-treinado, tendo já aprendido padrões e conhecimentos gerais da linguagem a partir de vastas quantidades de dados textuais, é então adaptado para seguir instruções através do processo de ajuste fino.
No entanto, em vez de carregar o menor modelo com 124 milhões de parâmetros, carregamos a versão média com 355 milhões de parâmetros, pois o modelo de 124 milhões é pequeno demais para alcançar resultados qualitativamente razoáveis através do ajuste fino por instrução. Isso é feito usando o mesmo código dos dois episódios anteriores, exceto que agora especificamos "gpt2-medium (355M)" em vez de "gpt2-small (124M)", ou seja, estamos usando um modelo maior para obter melhores resultados.
Observe que a execução do código fornecido abaixo iniciará o download da versão média do modelo GPT, que tem um requisito de armazenamento de aproximadamente 1,42 gigabytes. Este é mais ou menos três vezes maior do que o espaço de armazenamento necessário para o modelo pequeno:
pip install 'tensorflow[and-cuda]'
Requirement already satisfied: tensorflow[and-cuda] in /usr/local/lib/python3.12/dist-packages (2.19.0) Requirement already satisfied: absl-py>=1.0.0 in /usr/local/lib/python3.12/dist-packages (from tensorflow[and-cuda]) (1.4.0) Requirement already satisfied: astunparse>=1.6.0 in /usr/local/lib/python3.12/dist-packages (from tensorflow[and-cuda]) (1.6.3) Requirement already satisfied: flatbuffers>=24.3.25 in /usr/local/lib/python3.12/dist-packages (from tensorflow[and-cuda]) (25.9.23) Requirement already satisfied: gast!=0.5.0,!=0.5.1,!=0.5.2,>=0.2.1 in /usr/local/lib/python3.12/dist-packages (from tensorflow[and-cuda]) (0.6.0) Requirement already satisfied: google-pasta>=0.1.1 in /usr/local/lib/python3.12/dist-packages (from tensorflow[and-cuda]) (0.2.0) Requirement already satisfied: libclang>=13.0.0 in /usr/local/lib/python3.12/dist-packages (from tensorflow[and-cuda]) (18.1.1) Requirement already satisfied: opt-einsum>=2.3.2 in /usr/local/lib/python3.12/dist-packages (from tensorflow[and-cuda]) (3.4.0) Requirement already satisfied: packaging in /usr/local/lib/python3.12/dist-packages (from tensorflow[and-cuda]) (25.0) Requirement already satisfied: protobuf!=4.21.0,!=4.21.1,!=4.21.2,!=4.21.3,!=4.21.4,!=4.21.5,<6.0.0dev,>=3.20.3 in /usr/local/lib/python3.12/dist-packages (from tensorflow[and-cuda]) (5.29.5) Requirement already satisfied: requests<3,>=2.21.0 in /usr/local/lib/python3.12/dist-packages (from tensorflow[and-cuda]) (2.32.4) Requirement already satisfied: setuptools in /usr/local/lib/python3.12/dist-packages (from tensorflow[and-cuda]) (75.2.0) Requirement already satisfied: six>=1.12.0 in /usr/local/lib/python3.12/dist-packages (from tensorflow[and-cuda]) (1.17.0) Requirement already satisfied: termcolor>=1.1.0 in /usr/local/lib/python3.12/dist-packages (from tensorflow[and-cuda]) (3.1.0) Requirement already satisfied: typing-extensions>=3.6.6 in /usr/local/lib/python3.12/dist-packages (from tensorflow[and-cuda]) (4.15.0) Requirement already satisfied: wrapt>=1.11.0 in /usr/local/lib/python3.12/dist-packages (from tensorflow[and-cuda]) (1.17.3) Requirement already satisfied: grpcio<2.0,>=1.24.3 in /usr/local/lib/python3.12/dist-packages (from tensorflow[and-cuda]) (1.75.1) Requirement already satisfied: tensorboard~=2.19.0 in /usr/local/lib/python3.12/dist-packages (from tensorflow[and-cuda]) (2.19.0) Requirement already satisfied: keras>=3.5.0 in /usr/local/lib/python3.12/dist-packages (from tensorflow[and-cuda]) (3.10.0) Requirement already satisfied: numpy<2.2.0,>=1.26.0 in /usr/local/lib/python3.12/dist-packages (from tensorflow[and-cuda]) (2.0.2) Requirement already satisfied: h5py>=3.11.0 in /usr/local/lib/python3.12/dist-packages (from tensorflow[and-cuda]) (3.14.0) Requirement already satisfied: ml-dtypes<1.0.0,>=0.5.1 in /usr/local/lib/python3.12/dist-packages (from tensorflow[and-cuda]) (0.5.3) Collecting nvidia-cublas-cu12==12.5.3.2 (from tensorflow[and-cuda]) Downloading nvidia_cublas_cu12-12.5.3.2-py3-none-manylinux2014_x86_64.whl.metadata (1.5 kB) Collecting nvidia-cuda-cupti-cu12==12.5.82 (from tensorflow[and-cuda]) Downloading nvidia_cuda_cupti_cu12-12.5.82-py3-none-manylinux2014_x86_64.whl.metadata (1.6 kB) Requirement already satisfied: nvidia-cuda-nvcc-cu12==12.5.82 in /usr/local/lib/python3.12/dist-packages (from tensorflow[and-cuda]) (12.5.82) Collecting nvidia-cuda-nvrtc-cu12==12.5.82 (from tensorflow[and-cuda]) Downloading nvidia_cuda_nvrtc_cu12-12.5.82-py3-none-manylinux2014_x86_64.whl.metadata (1.5 kB) Collecting nvidia-cuda-runtime-cu12==12.5.82 (from tensorflow[and-cuda]) Downloading nvidia_cuda_runtime_cu12-12.5.82-py3-none-manylinux2014_x86_64.whl.metadata (1.5 kB) Collecting nvidia-cudnn-cu12==9.3.0.75 (from tensorflow[and-cuda]) Downloading nvidia_cudnn_cu12-9.3.0.75-py3-none-manylinux2014_x86_64.whl.metadata (1.6 kB) Collecting nvidia-cufft-cu12==11.2.3.61 (from tensorflow[and-cuda]) Downloading nvidia_cufft_cu12-11.2.3.61-py3-none-manylinux2014_x86_64.whl.metadata (1.5 kB) Collecting nvidia-curand-cu12==10.3.6.82 (from tensorflow[and-cuda]) Downloading nvidia_curand_cu12-10.3.6.82-py3-none-manylinux2014_x86_64.whl.metadata (1.5 kB) Collecting nvidia-cusolver-cu12==11.6.3.83 (from tensorflow[and-cuda]) Downloading nvidia_cusolver_cu12-11.6.3.83-py3-none-manylinux2014_x86_64.whl.metadata (1.6 kB) Collecting nvidia-cusparse-cu12==12.5.1.3 (from tensorflow[and-cuda]) Downloading nvidia_cusparse_cu12-12.5.1.3-py3-none-manylinux2014_x86_64.whl.metadata (1.6 kB) Collecting nvidia-nccl-cu12==2.23.4 (from tensorflow[and-cuda]) Downloading nvidia_nccl_cu12-2.23.4-py3-none-manylinux2014_x86_64.whl.metadata (1.8 kB) Collecting nvidia-nvjitlink-cu12==12.5.82 (from tensorflow[and-cuda]) Downloading nvidia_nvjitlink_cu12-12.5.82-py3-none-manylinux2014_x86_64.whl.metadata (1.5 kB) Requirement already satisfied: wheel<1.0,>=0.23.0 in /usr/local/lib/python3.12/dist-packages (from astunparse>=1.6.0->tensorflow[and-cuda]) (0.45.1) Requirement already satisfied: rich in /usr/local/lib/python3.12/dist-packages (from keras>=3.5.0->tensorflow[and-cuda]) (13.9.4) Requirement already satisfied: namex in /usr/local/lib/python3.12/dist-packages (from keras>=3.5.0->tensorflow[and-cuda]) (0.1.0) Requirement already satisfied: optree in /usr/local/lib/python3.12/dist-packages (from keras>=3.5.0->tensorflow[and-cuda]) (0.17.0) Requirement already satisfied: charset_normalizer<4,>=2 in /usr/local/lib/python3.12/dist-packages (from requests<3,>=2.21.0->tensorflow[and-cuda]) (3.4.3) Requirement already satisfied: idna<4,>=2.5 in /usr/local/lib/python3.12/dist-packages (from requests<3,>=2.21.0->tensorflow[and-cuda]) (3.10) Requirement already satisfied: urllib3<3,>=1.21.1 in /usr/local/lib/python3.12/dist-packages (from requests<3,>=2.21.0->tensorflow[and-cuda]) (2.5.0) Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.12/dist-packages (from requests<3,>=2.21.0->tensorflow[and-cuda]) (2025.10.5) Requirement already satisfied: markdown>=2.6.8 in /usr/local/lib/python3.12/dist-packages (from tensorboard~=2.19.0->tensorflow[and-cuda]) (3.9) Requirement already satisfied: tensorboard-data-server<0.8.0,>=0.7.0 in /usr/local/lib/python3.12/dist-packages (from tensorboard~=2.19.0->tensorflow[and-cuda]) (0.7.2) Requirement already satisfied: werkzeug>=1.0.1 in /usr/local/lib/python3.12/dist-packages (from tensorboard~=2.19.0->tensorflow[and-cuda]) (3.1.3) Requirement already satisfied: MarkupSafe>=2.1.1 in /usr/local/lib/python3.12/dist-packages (from werkzeug>=1.0.1->tensorboard~=2.19.0->tensorflow[and-cuda]) (3.0.3) Requirement already satisfied: markdown-it-py>=2.2.0 in /usr/local/lib/python3.12/dist-packages (from rich->keras>=3.5.0->tensorflow[and-cuda]) (4.0.0) Requirement already satisfied: pygments<3.0.0,>=2.13.0 in /usr/local/lib/python3.12/dist-packages (from rich->keras>=3.5.0->tensorflow[and-cuda]) (2.19.2) Requirement already satisfied: mdurl~=0.1 in /usr/local/lib/python3.12/dist-packages (from markdown-it-py>=2.2.0->rich->keras>=3.5.0->tensorflow[and-cuda]) (0.1.2) Downloading nvidia_cublas_cu12-12.5.3.2-py3-none-manylinux2014_x86_64.whl (363.3 MB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 363.3/363.3 MB 4.0 MB/s eta 0:00:00 Downloading nvidia_cuda_cupti_cu12-12.5.82-py3-none-manylinux2014_x86_64.whl (13.8 MB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 13.8/13.8 MB 101.1 MB/s eta 0:00:00 Downloading nvidia_cuda_nvrtc_cu12-12.5.82-py3-none-manylinux2014_x86_64.whl (24.9 MB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 24.9/24.9 MB 83.4 MB/s eta 0:00:00 Downloading nvidia_cuda_runtime_cu12-12.5.82-py3-none-manylinux2014_x86_64.whl (895 kB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 895.7/895.7 kB 63.8 MB/s eta 0:00:00 Downloading nvidia_cudnn_cu12-9.3.0.75-py3-none-manylinux2014_x86_64.whl (577.2 MB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 577.2/577.2 MB 975.1 kB/s eta 0:00:00 Downloading nvidia_cufft_cu12-11.2.3.61-py3-none-manylinux2014_x86_64.whl (192.5 MB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 192.5/192.5 MB 6.4 MB/s eta 0:00:00 Downloading nvidia_curand_cu12-10.3.6.82-py3-none-manylinux2014_x86_64.whl (56.3 MB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 56.3/56.3 MB 13.9 MB/s eta 0:00:00 Downloading nvidia_cusolver_cu12-11.6.3.83-py3-none-manylinux2014_x86_64.whl (130.3 MB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 130.3/130.3 MB 7.7 MB/s eta 0:00:00 Downloading nvidia_cusparse_cu12-12.5.1.3-py3-none-manylinux2014_x86_64.whl (217.6 MB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 217.6/217.6 MB 6.2 MB/s eta 0:00:00 Downloading nvidia_nccl_cu12-2.23.4-py3-none-manylinux2014_x86_64.whl (199.0 MB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 199.0/199.0 MB 5.5 MB/s eta 0:00:00 Downloading nvidia_nvjitlink_cu12-12.5.82-py3-none-manylinux2014_x86_64.whl (21.3 MB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 21.3/21.3 MB 108.3 MB/s eta 0:00:00 Installing collected packages: nvidia-nvjitlink-cu12, nvidia-nccl-cu12, nvidia-curand-cu12, nvidia-cuda-runtime-cu12, nvidia-cuda-nvrtc-cu12, nvidia-cuda-cupti-cu12, nvidia-cublas-cu12, nvidia-cusparse-cu12, nvidia-cufft-cu12, nvidia-cudnn-cu12, nvidia-cusolver-cu12 Attempting uninstall: nvidia-nvjitlink-cu12 Found existing installation: nvidia-nvjitlink-cu12 12.6.85 Uninstalling nvidia-nvjitlink-cu12-12.6.85: Successfully uninstalled nvidia-nvjitlink-cu12-12.6.85 Attempting uninstall: nvidia-nccl-cu12 Found existing installation: nvidia-nccl-cu12 2.27.3 Uninstalling nvidia-nccl-cu12-2.27.3: Successfully uninstalled nvidia-nccl-cu12-2.27.3 Attempting uninstall: nvidia-curand-cu12 Found existing installation: nvidia-curand-cu12 10.3.7.77 Uninstalling nvidia-curand-cu12-10.3.7.77: Successfully uninstalled nvidia-curand-cu12-10.3.7.77 Attempting uninstall: nvidia-cuda-runtime-cu12 Found existing installation: nvidia-cuda-runtime-cu12 12.6.77 Uninstalling nvidia-cuda-runtime-cu12-12.6.77: Successfully uninstalled nvidia-cuda-runtime-cu12-12.6.77 Attempting uninstall: nvidia-cuda-nvrtc-cu12 Found existing installation: nvidia-cuda-nvrtc-cu12 12.6.77 Uninstalling nvidia-cuda-nvrtc-cu12-12.6.77: Successfully uninstalled nvidia-cuda-nvrtc-cu12-12.6.77 Attempting uninstall: nvidia-cuda-cupti-cu12 Found existing installation: nvidia-cuda-cupti-cu12 12.6.80 Uninstalling nvidia-cuda-cupti-cu12-12.6.80: Successfully uninstalled nvidia-cuda-cupti-cu12-12.6.80 Attempting uninstall: nvidia-cublas-cu12 Found existing installation: nvidia-cublas-cu12 12.6.4.1 Uninstalling nvidia-cublas-cu12-12.6.4.1: Successfully uninstalled nvidia-cublas-cu12-12.6.4.1 Attempting uninstall: nvidia-cusparse-cu12 Found existing installation: nvidia-cusparse-cu12 12.5.4.2 Uninstalling nvidia-cusparse-cu12-12.5.4.2: Successfully uninstalled nvidia-cusparse-cu12-12.5.4.2 Attempting uninstall: nvidia-cufft-cu12 Found existing installation: nvidia-cufft-cu12 11.3.0.4 Uninstalling nvidia-cufft-cu12-11.3.0.4: Successfully uninstalled nvidia-cufft-cu12-11.3.0.4 Attempting uninstall: nvidia-cudnn-cu12 Found existing installation: nvidia-cudnn-cu12 9.10.2.21 Uninstalling nvidia-cudnn-cu12-9.10.2.21: Successfully uninstalled nvidia-cudnn-cu12-9.10.2.21 Attempting uninstall: nvidia-cusolver-cu12 Found existing installation: nvidia-cusolver-cu12 11.7.1.2 Uninstalling nvidia-cusolver-cu12-11.7.1.2: Successfully uninstalled nvidia-cusolver-cu12-11.7.1.2 ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts. torch 2.8.0+cu126 requires nvidia-cublas-cu12==12.6.4.1; platform_system == "Linux" and platform_machine == "x86_64", but you have nvidia-cublas-cu12 12.5.3.2 which is incompatible. torch 2.8.0+cu126 requires nvidia-cuda-cupti-cu12==12.6.80; platform_system == "Linux" and platform_machine == "x86_64", but you have nvidia-cuda-cupti-cu12 12.5.82 which is incompatible. torch 2.8.0+cu126 requires nvidia-cuda-nvrtc-cu12==12.6.77; platform_system == "Linux" and platform_machine == "x86_64", but you have nvidia-cuda-nvrtc-cu12 12.5.82 which is incompatible. torch 2.8.0+cu126 requires nvidia-cuda-runtime-cu12==12.6.77; platform_system == "Linux" and platform_machine == "x86_64", but you have nvidia-cuda-runtime-cu12 12.5.82 which is incompatible. torch 2.8.0+cu126 requires nvidia-cudnn-cu12==9.10.2.21; platform_system == "Linux" and platform_machine == "x86_64", but you have nvidia-cudnn-cu12 9.3.0.75 which is incompatible. torch 2.8.0+cu126 requires nvidia-cufft-cu12==11.3.0.4; platform_system == "Linux" and platform_machine == "x86_64", but you have nvidia-cufft-cu12 11.2.3.61 which is incompatible. torch 2.8.0+cu126 requires nvidia-curand-cu12==10.3.7.77; platform_system == "Linux" and platform_machine == "x86_64", but you have nvidia-curand-cu12 10.3.6.82 which is incompatible. torch 2.8.0+cu126 requires nvidia-cusolver-cu12==11.7.1.2; platform_system == "Linux" and platform_machine == "x86_64", but you have nvidia-cusolver-cu12 11.6.3.83 which is incompatible. torch 2.8.0+cu126 requires nvidia-cusparse-cu12==12.5.4.2; platform_system == "Linux" and platform_machine == "x86_64", but you have nvidia-cusparse-cu12 12.5.1.3 which is incompatible. torch 2.8.0+cu126 requires nvidia-nccl-cu12==2.27.3; platform_system == "Linux" and platform_machine == "x86_64", but you have nvidia-nccl-cu12 2.23.4 which is incompatible. torch 2.8.0+cu126 requires nvidia-nvjitlink-cu12==12.6.85; platform_system == "Linux" and platform_machine == "x86_64", but you have nvidia-nvjitlink-cu12 12.5.82 which is incompatible. Successfully installed nvidia-cublas-cu12-12.5.3.2 nvidia-cuda-cupti-cu12-12.5.82 nvidia-cuda-nvrtc-cu12-12.5.82 nvidia-cuda-runtime-cu12-12.5.82 nvidia-cudnn-cu12-9.3.0.75 nvidia-cufft-cu12-11.2.3.61 nvidia-curand-cu12-10.3.6.82 nvidia-cusolver-cu12-11.6.3.83 nvidia-cusparse-cu12-12.5.1.3 nvidia-nccl-cu12-2.23.4 nvidia-nvjitlink-cu12-12.5.82
# These are the same definitions we have used before:
import os
import requests
import json
import numpy as np
import tensorflow as tf
from tqdm import tqdm
def download_and_load_gpt2(model_size, models_dir):
# Validate model size
allowed_sizes = ("124M", "355M", "774M", "1558M")
if model_size not in allowed_sizes:
raise ValueError(f"Model size not in {allowed_sizes}")
# Define paths
model_dir = os.path.join(models_dir, model_size)
base_url = "https://openaipublic.blob.core.windows.net/gpt-2/models"
filenames = [
"checkpoint", "encoder.json", "hparams.json",
"model.ckpt.data-00000-of-00001", "model.ckpt.index",
"model.ckpt.meta", "vocab.bpe"
]
# Download files
os.makedirs(model_dir, exist_ok=True)
for filename in filenames:
file_url = os.path.join(base_url, model_size, filename)
file_path = os.path.join(model_dir, filename)
download_file(file_url, file_path)
# Load settings and params
tf_ckpt_path = tf.train.latest_checkpoint(model_dir)
settings = json.load(open(os.path.join(model_dir, "hparams.json")))
params = load_gpt2_params_from_tf_ckpt(tf_ckpt_path, settings)
return settings, params
def download_file(url, destination):
# Send a GET request to download the file in streaming mode
response = requests.get(url, stream=True)
# Get the total file size from headers, defaulting to 0 if not present
file_size = int(response.headers.get("content-length", 0))
# Check if file exists and has the same size
if os.path.exists(destination):
file_size_local = os.path.getsize(destination)
if file_size == file_size_local:
print(f"File already exists and is up-to-date: {destination}")
return
# Define the block size for reading the file
block_size = 1024 # 1 Kilobyte
# Initialize the progress bar with total file size
progress_bar_description = url.split("/")[-1] # Extract filename from URL
with tqdm(total=file_size, unit="iB", unit_scale=True, desc=progress_bar_description) as progress_bar:
# Open the destination file in binary write mode
with open(destination, "wb") as file:
# Iterate over the file data in chunks
for chunk in response.iter_content(block_size):
progress_bar.update(len(chunk)) # Update progress bar
file.write(chunk) # Write the chunk to the file
def load_gpt2_params_from_tf_ckpt(ckpt_path, settings):
# Initialize parameters dictionary with empty blocks for each layer
params = {"blocks": [{} for _ in range(settings["n_layer"])]}
# Iterate over each variable in the checkpoint
for name, _ in tf.train.list_variables(ckpt_path):
# Load the variable and remove singleton dimensions
variable_array = np.squeeze(tf.train.load_variable(ckpt_path, name))
# Process the variable name to extract relevant parts
variable_name_parts = name.split("/")[1:] # Skip the 'model/' prefix
# Identify the target dictionary for the variable
target_dict = params
if variable_name_parts[0].startswith("h"):
layer_number = int(variable_name_parts[0][1:])
target_dict = params["blocks"][layer_number]
# Recursively access or create nested dictionaries
for key in variable_name_parts[1:-1]:
target_dict = target_dict.setdefault(key, {})
# Assign the variable array to the last key
last_key = variable_name_parts[-1]
target_dict[last_key] = variable_array
return params
from llmdefinitions import GPTModel, load_weights_into_gpt
BASE_CONFIG = {
"vocab_size": 50257, # Vocabulary size
"context_length": 1024, # Context length
"drop_rate": 0.0, # Dropout rate
"qkv_bias": True # Query-key-value bias
}
model_configs = {
"gpt2-small (124M)": {"emb_dim": 768, "n_layers": 12, "n_heads": 12},
"gpt2-medium (355M)": {"emb_dim": 1024, "n_layers": 24, "n_heads": 16},
"gpt2-large (774M)": {"emb_dim": 1280, "n_layers": 36, "n_heads": 20},
"gpt2-xl (1558M)": {"emb_dim": 1600, "n_layers": 48, "n_heads": 25},
}
CHOOSE_MODEL = "gpt2-medium (355M)"
BASE_CONFIG.update(model_configs[CHOOSE_MODEL])
model_size = CHOOSE_MODEL.split(" ")[-1].lstrip("(").rstrip(")")
settings, params = download_and_load_gpt2(
model_size=model_size,
models_dir="gpt2"
)
model = GPTModel(BASE_CONFIG)
load_weights_into_gpt(model, params)
model.eval();
checkpoint: 100%|██████████| 77.0/77.0 [00:00<00:00, 263kiB/s] encoder.json: 100%|██████████| 1.04M/1.04M [00:00<00:00, 3.12MiB/s] hparams.json: 100%|██████████| 91.0/91.0 [00:00<00:00, 343kiB/s] model.ckpt.data-00000-of-00001: 100%|██████████| 1.42G/1.42G [01:39<00:00, 14.2MiB/s] model.ckpt.index: 100%|██████████| 10.4k/10.4k [00:00<00:00, 16.3MiB/s] model.ckpt.meta: 100%|██████████| 927k/927k [00:00<00:00, 2.32MiB/s] vocab.bpe: 100%|██████████| 456k/456k [00:00<00:00, 1.70MiB/s]
Antes de começarmos o ajuste fino do modelo, vamos ver como ele se comporta em uma das tarefas de validação comparando sua saída com a resposta esperada. Isso nos dará um entendimento inicial de quão bem o modelo se comporta em uma tarefa de seguimento de instruções logo de cara, antes do ajuste fino, e nos ajudará a apreciar o impacto do ajuste fino mais tarde.
torch.manual_seed(123)
input_text = format_input(val_data[0])
print(input_text)
Below is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: Convert the active sentence to passive: 'The chef cooks the meal every day.'
Em seguida, geramos a resposta do modelo usando a função generate que já implementamos:
from llmdefinitions import (
generate,
text_to_token_ids,
token_ids_to_text
)
token_ids = generate(
model=model,
idx=text_to_token_ids(input_text, tokenizer),
max_new_tokens=35,
context_size=BASE_CONFIG["context_length"],
eos_id=50256,
)
generated_text = token_ids_to_text(token_ids, tokenizer)
Note que a função generate retorna o texto de entrada e saída combinados. Esse comportamento foi conveniente em notebooks anteriores, já que os LLMs pré-treinados são projetados principalmente como modelos de completação de texto, onde a entrada e a saída são concatenadas para criar um texto coerente e legível. No entanto, ao avaliar o desempenho do modelo em uma tarefa específica, muitas vezes queremos nos concentrar apenas na resposta gerada pelo modelo.
Para isolar o texto da resposta do modelo, precisamos subtrair o comprimento da instrução de entrada do início do generated_text:
response_text = (
generated_text[len(input_text):]
.replace("### Response:", "")
.strip()
)
print(response_text)
The chef cooks the meal every day. ### Instruction: Convert the active sentence to passive: 'The chef cooks the
Este trecho de código remove o texto da entrada do início do generated_text, deixando-nos apenas com a resposta gerada pelo modelo. A função strip() é então aplicada para remover quaisquer caracteres de espaço em branco à esquerda ou à direita.
Como podemos ver, o modelo ainda não é capaz de seguir as instruções; ele cria uma seção "Resposta", mas simplesmente repete a frase original, bem como a instrução.
5. Finetuning com Instruction Data¶
Agora, focamos no ajuste fino (finetuning) do modelo. Pegamos o modelo pré-treinado carregado na seção anterior e o treinamos ainda mais usando o conjunto de dados de instruções preparado anteriormente.
Já fizemos todo o trabalho difícil quando implementamos o processamento do conjunto de dados de instruções no início deste notebook. Para o processo de ajuste fino em si, podemos reutilizar a função de cálculo da perda e as funções de treinamento implementadas durante o pré-treino:
from llmdefinitions import (
calc_loss_loader,
train_model_simple
)
Vamos calcular a perda inicial do conjunto de treinamento e validação antes de começar o treinamento (como em episódios anteriores, o objetivo é minimizar a perda).
model.to(device)
torch.manual_seed(123)
with torch.no_grad():
train_loss = calc_loss_loader(train_loader, model, device, num_batches=5)
val_loss = calc_loss_loader(val_loader, model, device, num_batches=5)
print("Training loss:", train_loss)
print("Validation loss:", val_loss)
Training loss: 3.825896167755127 Validation loss: 3.761921262741089
Note que o treinamento é um pouco mais caro do que em episódios anteriores, já que estamos usando um modelo maior (355 milhões de parâmetros em vez de 124 milhões). Os tempos de execução para vários dispositivos são mostrados abaixo para referência (executar este notebook em um dispositivo GPU compatível não requer alterações no código):
| Model | Device | Runtime for 2 Epochs |
|---|---|---|
| gpt2-medium (355M) | CPU (M3 MacBook Air) | 15.78 minutes |
| gpt2-medium (355M) | GPU (M3 MacBook Air) | 10.77 minutes |
| gpt2-medium (355M) | GPU (L4) | 1.83 minutes |
| gpt2-medium (355M) | GPU (A100) | 0.86 minutes |
| gpt2-small (124M) | CPU (M3 MacBook Air) | 5.74 minutes |
| gpt2-small (124M) | GPU (M3 MacBook Air) | 3.73 minutes |
| gpt2-small (124M) | GPU (L4) | 0.69 minutes |
| gpt2-small (124M) | GPU (A100) | 0.39 minutes |
Com o modelo e os carregadores de dados preparados, podemos prosseguir com o treinamento do modelo. O código a seguir configura o processo de treinamento, incluindo a inicialização do otimizador, definindo o número de épocas e definindo a frequência de avaliação e o contexto inicial para avaliar as respostas LLM geradas durante o treinamento com base na primeira instrução do conjunto de validação (val_data[0]) que examinamos anteriormente:
import time
start_time = time.time()
torch.manual_seed(123)
optimizer = torch.optim.AdamW(model.parameters(), lr=0.00005, weight_decay=0.1)
num_epochs = 2
train_losses, val_losses, tokens_seen = train_model_simple(
model, train_loader, val_loader, optimizer, device,
num_epochs=num_epochs, eval_freq=5, eval_iter=5,
start_context=format_input(val_data[0]), tokenizer=tokenizer
)
end_time = time.time()
execution_time_minutes = (end_time - start_time) / 60
print(f"Training completed in {execution_time_minutes:.2f} minutes.")
Ep 1 (Step 000000): Train loss 2.637, Val loss 2.626 Ep 1 (Step 000005): Train loss 1.174, Val loss 1.102 Ep 1 (Step 000010): Train loss 0.872, Val loss 0.945
A saída exibe o progresso do treinamento ao longo de duas épocas, onde a diminuição constante das perdas indica uma capacidade crescente de seguir instruções e gerar respostas apropriadas; portanto, o modelo treina bem. (Como o modelo demonstrou aprendizado eficaz nessas duas épocas, estender o treinamento para uma terceira época ou mais não é essencial e pode até ser contraproducente aqui, pois poderia levar a um aumento do sobreajuste.)
Além disso, com base no texto da resposta impresso após cada época, podemos ver que o modelo segue corretamente a instrução de converter a frase de entrada 'The chef cooks the meal every day.' para voz passiva 'The meal is cooked every day by the chef.' (Formatar e avaliar as respostas adequadamente mais tarde).
Finalmente, vamos dar uma olhada nas curvas de perda de treinamento e validação:
from llmdefinitions import plot_losses
epochs_tensor = torch.linspace(0, num_epochs, len(train_losses))
plot_losses(epochs_tensor, tokens_seen, train_losses, val_losses)
A linha sólida representa a perda de treinamento, mostrando uma diminuição acentuada antes de se estabilizar, enquanto a linha tracejada representa a perda de validação, que segue um padrão semelhante.
Como podemos ver, a perda diminui acentuadamente no início da primeira época, o que significa que o modelo começa a aprender rapidamente. Também podemos ver que um leve sobreajuste se instala por volta de 1 época de treinamento.
6. Extraindo e Salvando a Respostas¶
Depois de afinar o LLM na parte de treinamento do conjunto de instruções, agora prosseguimos para avaliar seu desempenho no conjunto de teste reservado. Para isso, primeiro extraímos as respostas geradas pelo modelo para cada entrada do conjunto de teste e as coletamos para análise manual, como ilustrado no panorama apresentado no início deste notebook.
Começamos com o passo 7, a etapa de instrução de resposta, utilizando a função generate. A função generate retorna o texto combinado (entrada + saída), então usamos fatiamento (slicing) e o método .replace() sobre o conteúdo da variável generated_text para extrair apenas a resposta do modelo. Em seguida, imprimimos as respostas do modelo ao lado das respostas esperadas do conjunto de teste para os três primeiros itens, apresentando-as lado a lado para comparação:
torch.manual_seed(123)
for entry in test_data[:3]: # Iterate over the first 3 test set samples
input_text = format_input(entry)
token_ids = generate( # Use the generate function imported earlier
model=model,
idx=text_to_token_ids(input_text, tokenizer).to(device),
max_new_tokens=256,
context_size=BASE_CONFIG["context_length"],
eos_id=50256
)
generated_text = token_ids_to_text(token_ids, tokenizer)
response_text = (
generated_text[len(input_text):]
.replace("### Response:", "")
.strip()
)
print(input_text)
print(f"\nCorrect response:\n>> {entry['output']}")
print(f"\nModel response:\n>> {response_text.strip()}")
print("-------------------------------------")
Como podemos observar com base nas instruções do conjunto de teste, nas respostas fornecidas e nas respostas do modelo, o desempenho do modelo é relativamente bom. As respostas à primeira e última instrução estão claramente corretas. A segunda resposta está próxima; o modelo responde com “cumulus cloud” em vez de “cumulonimbus” (no entanto, observe que nuvens cumulus podem evoluir para nuvens cumulonimbus, que são capazes de produzir tempestades).
O mais importante é perceber que a avaliação do modelo não é tão direta quanto no notebook anterior, onde bastava calcular a porcentagem de rótulos corretos de spam/não‑spam para obter a acurácia de classificação. Na prática, LLMs finetunados com instruções, como chatbots, são avaliados por múltiplas abordagens:
Benchmarks de respostas curtas e escolha múltipla (ex.: MMLU – “Measuring Massive Multitask Language Understanding”, https://arxiv.org/abs/2009.03300), que testam o conhecimento do modelo;
Comparação de preferência humana com outros LLMs, como a arena de chatbots LMSYS (https://arena.lmsys.org);
Benchmarks conversacionais automatizados, onde outro LLM (por exemplo, GPT‑4) avalia as respostas, como AlpacaEval (https://tatsu-lab.github.io/alpaca_eval/).
Na prática, pode ser útil considerar os três tipos de métodos de avaliação: perguntas de múltipla escolha, avaliação humana e métricas automatizadas que medem o desempenho conversacional. Entretanto, visto que nosso foco principal é avaliar o desempenho em diálogos ao invés da mera capacidade de responder a questões de múltipla escolha, os métodos 2 (avaliação humana) e 3 (métricas automatizadas) podem ser mais relevantes. Considerando a escala da tarefa, implementaremos uma abordagem semelhante à do método 3, que envolve avaliar as respostas automaticamente usando outro LLM. Isso nos permitirá medir eficientemente a qualidade das respostas geradas sem necessidade de envolvimento humano extensivo, economizando tempo e recursos enquanto ainda obtemos indicadores significativos de desempenho.
Na próxima seção, usaremos um procedimento parecido com o AlpacaEval e empregaremos outro LLM para avaliar as respostas do nosso modelo; porém, utilizaremos nosso próprio conjunto de teste ao invés de um dataset público. Isso possibilita uma avaliação mais direcionada e relevante do desempenho do modelo dentro do contexto dos casos de uso pretendidos representados em nosso conjunto de instruções. Para isso, anexamos as respostas geradas pelo modelo ao dicionário test_data e salvamos como arquivo "instruction-data-with-response.json" para fins de registro, permitindo que carreguemos e analisemos em sessões Python distintas, se necessário.
O código a seguir usa o método generate da mesma forma que antes; porém, agora iteramos sobre todo o test_set. Além disso, ao invés de imprimir as respostas do modelo, adicionamos elas ao dicionário test_set, ou seja, salvamos:
from tqdm import tqdm # use the progress bar library
for i, entry in tqdm(enumerate(test_data), total=len(test_data)):
input_text = format_input(entry)
token_ids = generate(
model=model,
idx=text_to_token_ids(input_text, tokenizer).to(device),
max_new_tokens=256,
context_size=BASE_CONFIG["context_length"],
eos_id=50256
)
generated_text = token_ids_to_text(token_ids, tokenizer)
response_text = generated_text[len(input_text):].replace("### Response:", "").strip()
test_data[i]["model_response"] = response_text
with open("instruction-data-with-response.json", "w") as file:
json.dump(test_data, file, indent=4) # "indent" for pretty-printing
print(test_data[0])
Finalmente, salvamos o modelo como gpt2-medium355M-sft.pth:
import re
# Remove white spaces and parentheses from file name
file_name = f"{re.sub(r'[ ()]', '', CHOOSE_MODEL) }-sft.pth" # sft = supervised finetuning
torch.save(model.state_dict(), file_name)
print(f"Model saved as {file_name}")
# Load the model via
# model.load_state_dict(torch.load("gpt2-medium355M-sft.pth"))
7. Avaliando um LLM-AFI¶
Anteriormente, avaliamos o desempenho de um modelo finetunado com instruções examinando suas respostas em 3 exemplos do conjunto de teste. Embora isso nos dê uma ideia aproximada de quão bem o modelo funciona, esse método não escala bem para grandes volumes de respostas. Portanto, nesta seção, automatizamos a avaliação das respostas do LLM finetunado usando outro LLM maior. Em particular, utilizamos um modelo Llama 3 de 8 bilhões de parâmetros finetunado com instruções pela Meta AI que pode ser executado localmente via ollama (https://ollama.com), e implementamos uma técnica para quantificar o desempenho do modelo finetunado pontuando as respostas geradas pelo teste.
Ollama¶
O ollama é um aplicativo eficiente para gerenciar e interagir com grandes modelos de linguagem (LLMs) de forma prática, permitindo a execução desses modelos em laptops. Ele funciona como uma camada de abstração sobre a biblioteca open‑source llama.cpp (https://github.com/ggerganov/llama.cpp), que implementa LLMs em puro C/C++ para maximizar eficiência. Note que o Ollama é apenas uma ferramenta de inferência (geração de texto) e não suporta treinamento ou finetuning de LLMs.
Antes de rodar o código abaixo, instale o Ollama visitando https://ollama.com e seguindo as instruções (por exemplo, clique em “Download” e baixe a aplicação do Ollama para seu sistema operacional).
Em geral, antes de usar o Ollama via linha de comando, precisamos iniciar a aplicação ou executar ollama serve em um terminal separado.
A figura mostra duas opções para executar o Ollama. O painel esquerdo ilustra a inicialização usando ollama serve. O painel direito mostra uma segunda opção no macOS, executando a aplicação Ollama em segundo plano ao invés de usar o comando ollama serve.
Com a aplicação Ollama ou ollama serve rodando em outro terminal, na linha de comando execute:
# 8B model
ollama run llama3
A saída fica assim:
$ ollama run llama3
pulling manifest
pulling 6a0746a1ec1a... 100% ▕████████████████▏ 4.7 GB
pulling 4fa551d4f938... 100% ▕████████████████▏ 12 KB
pulling 8ab4849b038c... 100% ▕████████████████▏ 254 B
pulling 577073ffcc6c... 100% ▕████████████████▏ 110 B
pulling 3f8eb4da87fa... 100% ▕████████████████▏ 485 B
verifying sha256 digest
writing manifest
removing any unused layers
success
Obs.:
llama3refere-se ao modelo Llama 3 de 8 bilhões de parâmetros finetunado com instruções. Usar o Ollama com o modelo"llama3"requer 16 GB de RAM; se seu computador não suportar, você pode tentar um modelo menor, como o phi‑3 de 3.8B, definindomodel = "phi-3", que exige apenas 8 GB de RAM. Alternativamente, pode usar o modelo maior Llama 3 de 70 bilhões de parâmetros (se sua máquina suportar), substituindollama3porllama3:70b.
Depois da descarga, aparecerá um prompt na linha de comando permitindo conversar com o modelo. Por exemplo:
>>> What do llamas eat?
Llamas are ruminant animals, which means they have a four-chambered
stomach and eat plants that are high in fiber. In the wild, llamas
typically feed on:
1. Grasses: They love to graze on various types of grasses, including tall
grasses, wheat, oats, and barley.
Obs.: A resposta pode variar pois o Ollama não é determinístico no momento da escrita.
Você pode encerrar a sessão digitando /bye. Contudo, mantenha o comando ollama serve ou a aplicação Ollama em execução pelo restante desta etapa.
O código a seguir verifica se a sessão do Ollama está funcionando corretamente antes de prosseguir com a avaliação das respostas geradas no conjunto de teste da seção anterior:
import psutil
def check_if_running(process_name):
running = False
for proc in psutil.process_iter(["name"]):
if process_name in proc.info["name"]:
running = True
break
return running
ollama_running = check_if_running("ollama")
if not ollama_running:
raise RuntimeError("Ollama not running. Launch ollama before proceeding.")
print("Ollama running:", check_if_running("ollama"))
Certifique‑se de que a saída ao executar o código anterior exiba Ollama running: True.
Se aparecer False, verifique se o comando ollama serve ou o aplicativo Ollama está em execução ativa.
# This cell is optional; it allows you to restart the notebook
# and only run the previous section without rerunning any of the previous code
import json
from tqdm import tqdm
file_path = "instruction-data-with-response.json"
with open(file_path, "r") as file:
test_data = json.load(file)
def format_input(entry):
instruction_text = (
f"Below is an instruction that describes a task. "
f"Write a response that appropriately completes the request."
f"\n\n### Instruction:\n{entry['instruction']}"
)
input_text = f"\n\n### Input:\n{entry['input']}" if entry["input"] else ""
return instruction_text + input_text
Uma forma alternativa de usar o comando ollama run para interagir com o modelo é por meio da sua API REST em Python, usando a função abaixo. Antes de executar as próximas células deste notebook, garanta que o Ollama ainda esteja rodando. A função query_model demonstra como utilizar essa API:
import urllib.request
def query_model(
prompt,
model="llama3",
url="http://localhost:11434/api/chat"
):
# Create the data payload as a dictionary
data = {
"model": model,
"messages": [
{"role": "user", "content": prompt}
],
"options": { # Settings below are required for deterministic responses
"seed": 123,
"temperature": 0,
"num_ctx": 2048 # context size
}
}
# Convert the dictionary to a JSON formatted string and encode it to bytes
payload = json.dumps(data).encode("utf-8")
# Create a request object, setting the method to POST and adding necessary headers
request = urllib.request.Request(
url,
data=payload,
method="POST"
)
request.add_header("Content-Type", "application/json")
# Send the request and capture the response
response_data = ""
with urllib.request.urlopen(request) as response:
# Read and decode the response
while True:
line = response.readline().decode("utf-8")
if not line:
break
response_json = json.loads(line)
response_data += response_json["message"]["content"]
return response_data
# now an example of how to use the query_llama function just implemented
model = "llama3"
result = query_model("What do Llamas eat?", model)
print(result)
Com a função query_model definida acima, podemos avaliar as respostas geradas pelo nosso modelo finetunado com um prompt que instrui o Llama 3 a pontuar as respostas do nosso modelo em uma escala de 0 a 100, usando a resposta do conjunto de teste como referência.
Primeiro, aplicamos essa abordagem nos três primeiros exemplos do conjunto de teste que examinamos em uma seção anterior:
for entry in test_data[:3]:
prompt = (
f"Given the input `{format_input(entry)}` "
f"and correct output `{entry['output']}`, "
f"score the model response `{entry['model_response']}`"
f" on a scale from 0 to 100, where 100 is the best score. "
)
print("\nDataset response:")
print(">>", entry['output'])
print("\nModel response:")
print(">>", entry["model_response"])
print("\nScore:")
print(">>", query_model(prompt))
print("\n-------------------------")
Como podemos observar, o Llama 3 fornece uma avaliação razoável e também atribui pontos parciais quando o modelo não está totalmente correto, como no caso da resposta “cumulus cloud”. Note que o prompt original retorna avaliações muito detalhadas; podemos modificá‑lo para gerar apenas respostas inteiras entre 0 e 100 (onde 100 é a melhor pontuação). Essa modificação permite calcular uma média de pontuação do nosso modelo, oferecendo uma avaliação mais concisa e quantitativa.
A função generate_model_scores abaixo usa um prompt alterado que instrui o modelo a “Responder apenas com o número inteiro”. A avaliação dos 110 itens do conjunto de teste leva cerca de 1 minuto em um laptop MacBook Air M3.
def generate_model_scores(json_data, json_key, model="llama3"):
scores = []
for entry in tqdm(json_data, desc="Scoring entries"):
prompt = (
f"Given the input `{format_input(entry)}` "
f"and correct output `{entry['output']}`, "
f"score the model response `{entry[json_key]}`"
f" on a scale from 0 to 100, where 100 is the best score. "
f"Respond with the integer number only."
)
score = query_model(prompt, model)
try:
scores.append(int(score))
except ValueError:
print(f"Could not convert score: {score}")
continue
return scores
scores = generate_model_scores(test_data, "model_response")
print(f"Number of scores: {len(scores)} of {len(test_data)}")
print(f"Average score: {sum(scores)/len(scores):.2f}\n")
Nosso modelo alcança uma pontuação média de aproximadamente 50, que podemos usar como ponto de referência para comparar com outros modelos ou testar outras configurações de treinamento que possam melhorar o desempenho. Observe que o Ollama não é totalmente determinístico entre sistemas operacionais (até a data desta redação), então os números obtidos podem diferir ligeiramente dos mostrados acima.
Para referência, as pontuações originais são:
- Modelo base Llama 3 8B: 58,51
- Modelo Instruct Llama 3 8B: 82,65
Para melhorar ainda mais o desempenho do nosso modelo, podemos explorar várias estratégias, como:
- Ajustar os hiperparâmetros durante o finetuning (taxa de aprendizado, tamanho do lote, número de épocas).
- Aumentar o tamanho ou diversificar o conjunto de treinamento para cobrir uma gama maior de tópicos e estilos.
- Experimentar diferentes prompts ou formatos de instrução que guiem as respostas do modelo de forma mais eficaz.
- Considerar o uso de um modelo pré‑treinado maior, que pode ter maior capacidade de capturar padrões complexos e gerar respostas mais precisas.
8. Conclusão¶
Cobrimos as etapas principais do ciclo de desenvolvimento de LLMs: implementar uma arquitetura de LLM, pré‑treinar um LLM e fine‑tune‑á-lo.
Uma etapa opcional que às vezes é seguida após o fine‑tuning por instruções é o preference finetuning (fine‑tuning por preferência), que pode ser particularmente útil para personalizar um modelo de modo a se alinhar melhor com preferências específicas do usuário.
Você pode estar interessado em usar LLMs diferentes e mais poderosos para aplicações do mundo real. Para isso, pode considerar ferramentas populares como axolotl (https://github.com/OpenAccess-AI-Collective/axolotl) ou LitGPT (https://github.com/Lightning-AI/litgpt).
Os campos de IA e pesquisa em LLMs estão evoluindo num ritmo acelerado. Uma forma de acompanhar as últimas novidades é explorar artigos recentes no arXiv em https://arxiv.org/list/cs.LG/recent. Além disso, muitos pesquisadores e profissionais são muito ativos na divulgação e discussão das últimas inovações nas plataformas sociais como X (anteriormente Twitter) e Reddit. O subreddit r/LocalLLaMA, em particular, é um bom recurso para se conectar com a comunidade e ficar informado sobre as ferramentas e tendências mais recentes.