Redes Neurais Convolucionais (CNNs)#
Visão Computacional | Prof. Dr. Denis Mayr Lima Martins
Recap: MLP para o MNIST dataset#
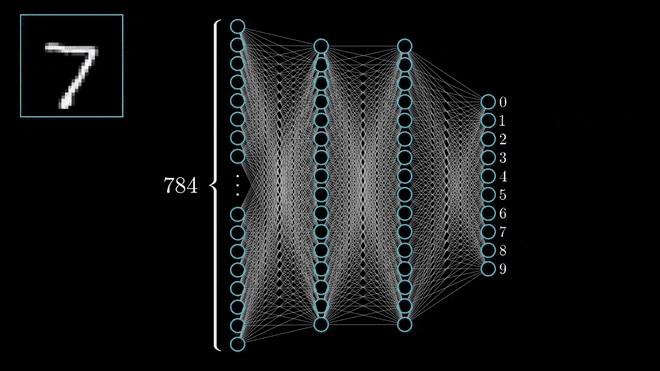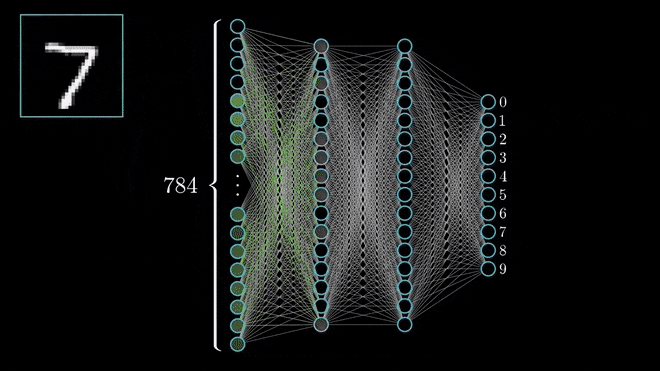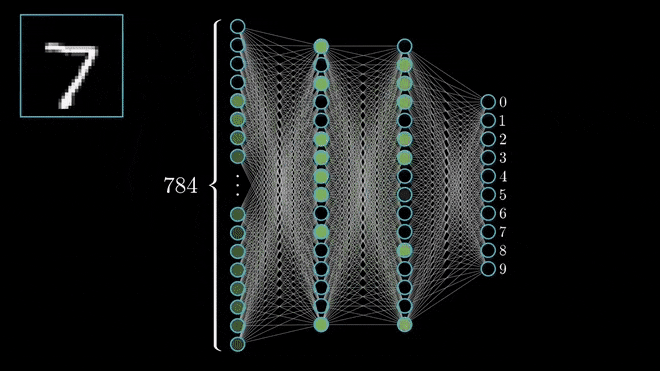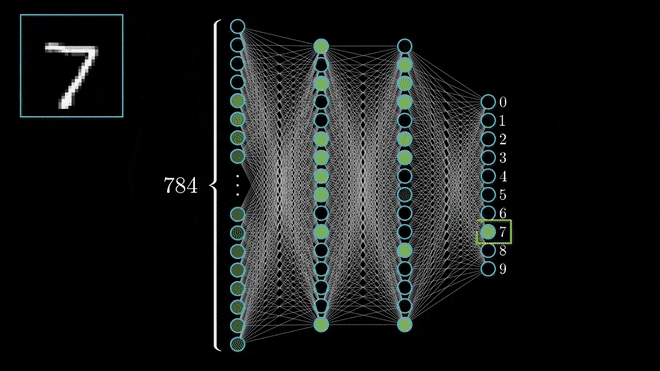
Neurônio da Camada Escondida#
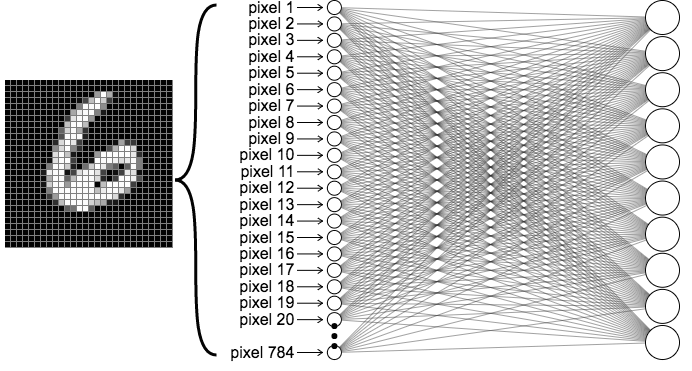 Rede de 1 camada para o MNIST dataset. Fonte: ML4a.
Rede de 1 camada para o MNIST dataset. Fonte: ML4a.
|
 Net input de um neurônio na camada escondida. Fonte: ML4a.
Net input de um neurônio na camada escondida. Fonte: ML4a.
|
Neurônio da Camada Escondida#
 Representação em Imagem de um Neurônio da Camada Escondida de uma MLP para o MNIST dataset. Fonte: ML4a.
Representação em Imagem de um Neurônio da Camada Escondida de uma MLP para o MNIST dataset. Fonte: ML4a.
Neurônio da Camada Escondida#
Limitações da Rede MLP#
Dimensionalidade Alta: Uma imagem 224x244x3 tem 150.528 pixels/entradas. Cada neurônio na primeira camada oculta de um MLP precisaria de 150.528 pesos, levando a bilhões de parâmetros treináveis em uma rede profunda.
O grande número de parâmetros torna o modelo propenso a overfitting (superajuste).
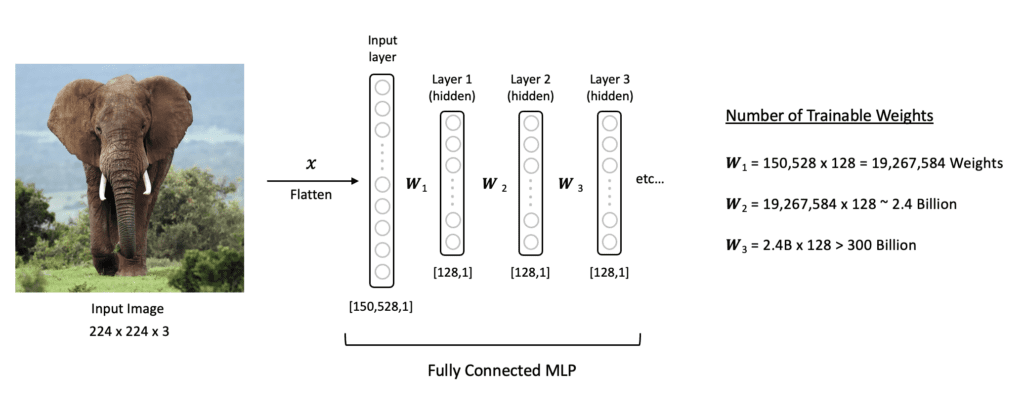 Alta dimensionalidade das MLPs para imagens. Frequentemente levando a overfitting. Fonte: LearnOpenCV.
Alta dimensionalidade das MLPs para imagens. Frequentemente levando a overfitting. Fonte: LearnOpenCV.
Limitações da Rede MLP#
Perda de Estrutura Espacial: MLPs exigem que a imagem 2D/3D seja “achatada” (flattened) em um vetor 1D.
Isso destrói a informação de localidade: pixels próximos (semânticos) são tratados da mesma forma que pixels distantes.
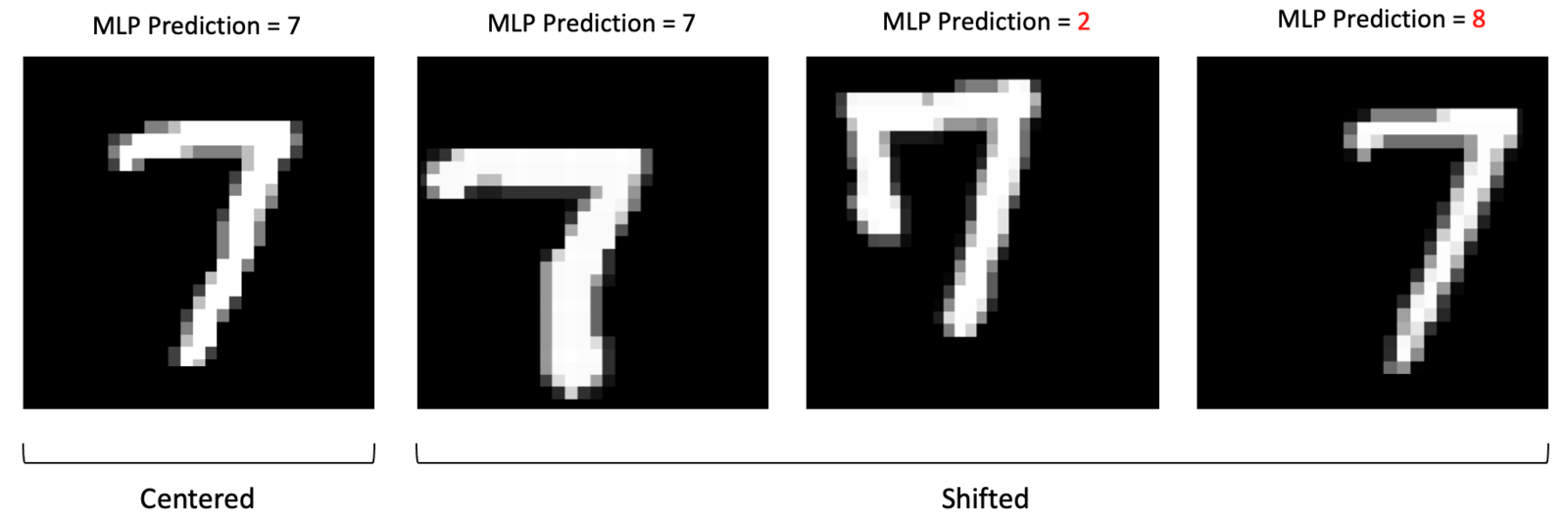
Objetivos de Aprendizagem#
Explicar por que CNNs são adequadas para dados de imagem.
Descrever os blocos fundamentais (convolução, padding, stride, pooling, ativação).
Esboçar uma arquitetura simples de CNN e justificar cada componente.
Implementar um CNN mínimo em PyTorch que classifica dígitos MNIST.
Redes Neurais Convolucionais#
Convolutional Neural Nets (CNNs ou ConvNets) são arquiteturas de redes neurais otimizadas para dados com estrutura de grade, como imagens.
CNN aplica uma série de transformações na imagem original (veja esquema abaixo) com três tipos de camadas (convolution, pooling e fully connected).
A sequência de camadas antes da camada fully connected é chamada de extrator de características.
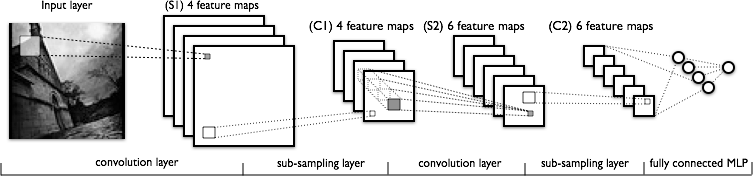
Demo de CNN para o MNIST#

CNN em Pytorch: Demo#
Código completo no site do professor: https://denmartins.github.io.
import torch.nn as nn
import torch.nn.functional as F
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.sequential = nn.Sequential(
# Primeira camada convolucional
nn.Conv2d(in_channels=1, out_channels=32,
kernel_size=2, padding=1),
nn.ReLU(),
# Segunda camada convolucional
nn.Conv2d(in_channels=32, out_channels=64,
kernel_size=2, padding=1),
# Pooling Max: 2x2
nn.MaxPool2d(kernel_size=2, stride=2),
# Flatten de matriz para vetor.
nn.Flatten(),
# Definindo as camadas FC
# Camada Totalmente Conectada 1
nn.Linear(14400, 128),
nn.ReLU(),
# Camada de Saída (10 classes para MNIST)
nn.Linear(128, 10)
)
def forward(self, x):
return self.sequential(x)
import matplotlib.pyplot as plt
import seaborn as sns
import torch
from torch import nn
import torch.optim as optim
import torch.utils.data as data
import torchvision.transforms as transforms
from torchvision import datasets
from tqdm.notebook import trange
A module that was compiled using NumPy 1.x cannot be run in
NumPy 2.2.5 as it may crash. To support both 1.x and 2.x
versions of NumPy, modules must be compiled with NumPy 2.0.
Some module may need to rebuild instead e.g. with 'pybind11>=2.12'.
If you are a user of the module, the easiest solution will be to
downgrade to 'numpy<2' or try to upgrade the affected module.
We expect that some modules will need time to support NumPy 2.
Traceback (most recent call last): File "<frozen runpy>", line 198, in _run_module_as_main
File "<frozen runpy>", line 88, in _run_code
File "/opt/anaconda3/lib/python3.11/site-packages/ipykernel_launcher.py", line 17, in <module>
app.launch_new_instance()
File "/opt/anaconda3/lib/python3.11/site-packages/traitlets/config/application.py", line 992, in launch_instance
app.start()
File "/opt/anaconda3/lib/python3.11/site-packages/ipykernel/kernelapp.py", line 701, in start
self.io_loop.start()
File "/opt/anaconda3/lib/python3.11/site-packages/tornado/platform/asyncio.py", line 195, in start
self.asyncio_loop.run_forever()
File "/opt/anaconda3/lib/python3.11/asyncio/base_events.py", line 607, in run_forever
self._run_once()
File "/opt/anaconda3/lib/python3.11/asyncio/base_events.py", line 1922, in _run_once
handle._run()
File "/opt/anaconda3/lib/python3.11/asyncio/events.py", line 80, in _run
self._context.run(self._callback, *self._args)
File "/opt/anaconda3/lib/python3.11/site-packages/ipykernel/kernelbase.py", line 534, in dispatch_queue
await self.process_one()
File "/opt/anaconda3/lib/python3.11/site-packages/ipykernel/kernelbase.py", line 523, in process_one
await dispatch(*args)
File "/opt/anaconda3/lib/python3.11/site-packages/ipykernel/kernelbase.py", line 429, in dispatch_shell
await result
File "/opt/anaconda3/lib/python3.11/site-packages/ipykernel/kernelbase.py", line 767, in execute_request
reply_content = await reply_content
File "/opt/anaconda3/lib/python3.11/site-packages/ipykernel/ipkernel.py", line 429, in do_execute
res = shell.run_cell(
File "/opt/anaconda3/lib/python3.11/site-packages/ipykernel/zmqshell.py", line 549, in run_cell
return super().run_cell(*args, **kwargs)
File "/opt/anaconda3/lib/python3.11/site-packages/IPython/core/interactiveshell.py", line 3051, in run_cell
result = self._run_cell(
File "/opt/anaconda3/lib/python3.11/site-packages/IPython/core/interactiveshell.py", line 3106, in _run_cell
result = runner(coro)
File "/opt/anaconda3/lib/python3.11/site-packages/IPython/core/async_helpers.py", line 129, in _pseudo_sync_runner
coro.send(None)
File "/opt/anaconda3/lib/python3.11/site-packages/IPython/core/interactiveshell.py", line 3311, in run_cell_async
has_raised = await self.run_ast_nodes(code_ast.body, cell_name,
File "/opt/anaconda3/lib/python3.11/site-packages/IPython/core/interactiveshell.py", line 3493, in run_ast_nodes
if await self.run_code(code, result, async_=asy):
File "/opt/anaconda3/lib/python3.11/site-packages/IPython/core/interactiveshell.py", line 3553, in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
File "/var/folders/p7/p37cm2fj10xgjrjj5rzdm66c0000gn/T/ipykernel_59224/4188437962.py", line 1, in <module>
import matplotlib.pyplot as plt
File "/opt/anaconda3/lib/python3.11/site-packages/matplotlib/__init__.py", line 161, in <module>
from . import _api, _version, cbook, _docstring, rcsetup
File "/opt/anaconda3/lib/python3.11/site-packages/matplotlib/rcsetup.py", line 27, in <module>
from matplotlib.colors import Colormap, is_color_like
File "/opt/anaconda3/lib/python3.11/site-packages/matplotlib/colors.py", line 57, in <module>
from matplotlib import _api, _cm, cbook, scale
File "/opt/anaconda3/lib/python3.11/site-packages/matplotlib/scale.py", line 22, in <module>
from matplotlib.ticker import (
File "/opt/anaconda3/lib/python3.11/site-packages/matplotlib/ticker.py", line 143, in <module>
from matplotlib import transforms as mtransforms
File "/opt/anaconda3/lib/python3.11/site-packages/matplotlib/transforms.py", line 49, in <module>
from matplotlib._path import (
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
AttributeError: _ARRAY_API not found
---------------------------------------------------------------------------
ImportError Traceback (most recent call last)
Cell In[2], line 1
----> 1 import matplotlib.pyplot as plt
2 import seaborn as sns
3 import torch
File /opt/anaconda3/lib/python3.11/site-packages/matplotlib/__init__.py:161
157 from packaging.version import parse as parse_version
159 # cbook must import matplotlib only within function
160 # definitions, so it is safe to import from it here.
--> 161 from . import _api, _version, cbook, _docstring, rcsetup
162 from matplotlib.cbook import sanitize_sequence
163 from matplotlib._api import MatplotlibDeprecationWarning
File /opt/anaconda3/lib/python3.11/site-packages/matplotlib/rcsetup.py:27
25 from matplotlib import _api, cbook
26 from matplotlib.cbook import ls_mapper
---> 27 from matplotlib.colors import Colormap, is_color_like
28 from matplotlib._fontconfig_pattern import parse_fontconfig_pattern
29 from matplotlib._enums import JoinStyle, CapStyle
File /opt/anaconda3/lib/python3.11/site-packages/matplotlib/colors.py:57
55 import matplotlib as mpl
56 import numpy as np
---> 57 from matplotlib import _api, _cm, cbook, scale
58 from ._color_data import BASE_COLORS, TABLEAU_COLORS, CSS4_COLORS, XKCD_COLORS
61 class _ColorMapping(dict):
File /opt/anaconda3/lib/python3.11/site-packages/matplotlib/scale.py:22
20 import matplotlib as mpl
21 from matplotlib import _api, _docstring
---> 22 from matplotlib.ticker import (
23 NullFormatter, ScalarFormatter, LogFormatterSciNotation, LogitFormatter,
24 NullLocator, LogLocator, AutoLocator, AutoMinorLocator,
25 SymmetricalLogLocator, AsinhLocator, LogitLocator)
26 from matplotlib.transforms import Transform, IdentityTransform
29 class ScaleBase:
File /opt/anaconda3/lib/python3.11/site-packages/matplotlib/ticker.py:143
141 import matplotlib as mpl
142 from matplotlib import _api, cbook
--> 143 from matplotlib import transforms as mtransforms
145 _log = logging.getLogger(__name__)
147 __all__ = ('TickHelper', 'Formatter', 'FixedFormatter',
148 'NullFormatter', 'FuncFormatter', 'FormatStrFormatter',
149 'StrMethodFormatter', 'ScalarFormatter', 'LogFormatter',
(...)
155 'MultipleLocator', 'MaxNLocator', 'AutoMinorLocator',
156 'SymmetricalLogLocator', 'AsinhLocator', 'LogitLocator')
File /opt/anaconda3/lib/python3.11/site-packages/matplotlib/transforms.py:49
46 from numpy.linalg import inv
48 from matplotlib import _api
---> 49 from matplotlib._path import (
50 affine_transform, count_bboxes_overlapping_bbox, update_path_extents)
51 from .path import Path
53 DEBUG = False
ImportError: numpy.core.multiarray failed to import
# Número de processos para o dataloader
NUM_WORKERS = 0
# Quantas amostras (imagens) por batch
BATCH_SIZE = 128
# Converte dados em tensores
transform = transforms.ToTensor()
# Carrega dados de treino e teste
train_data = datasets.MNIST(root='data', train=True,
download=True, transform=transform)
test_data = datasets.MNIST(root='data', train=False,
download=True, transform=transform)
# Cria dataset de validação
VALIDATION_SIZE = 0.1
n_train_examples = int(len(train_data) * VALIDATION_SIZE)
n_valid_examples = len(train_data) - n_train_examples
train_data, valid_data = data.random_split(
train_data, [n_train_examples, n_valid_examples])
# Data Loaders
train_loader = torch.utils.data.DataLoader(train_data, shuffle=True,
batch_size=BATCH_SIZE, num_workers=NUM_WORKERS)
valid_loader = torch.utils.data.DataLoader(valid_data,
batch_size=BATCH_SIZE, num_workers=NUM_WORKERS)
test_loader = torch.utils.data.DataLoader(test_data,
batch_size=BATCH_SIZE, num_workers=NUM_WORKERS)
def set_device(on_gpu=True):
has_mps = torch.backends.mps.is_available()
has_cuda = torch.cuda.is_available()
return "mps" if (has_mps and on_gpu) \
else "cuda" if (has_cuda and on_gpu) \
else "cpu"
torch.manual_seed(42)
EPOCHS = 10
device = set_device(on_gpu=True)
model = SimpleCNN()
model = model.to(device)
loss_function = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
num_parameters = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f"Num. Parâmetros no modelo:", num_parameters)
Num. Parâmetros no modelo: 1853034
def correct(output, target):
predicted_digits = output.argmax(1) # Posição com maior valor da saída
correct_ones = (predicted_digits == target).type(torch.float) # 1.0 se acertou, 0.0 caso contrário
return correct_ones.sum().item() # Conta o número de acertos
def train_model_mini_batch_with_validation(epochs, train_loader, valid_loader, model, loss_function, optimizer):
tr_loss = [0.]*epochs
val_loss = [0.]*epochs
with trange(epochs, desc="Training", leave=False) as tepoch:
for epoch in range(epochs):
model.train()
train_total_loss = 0.0
total_correct = 0.0
for data, target in train_loader:
# Copia dados para o device (ex.: GPU)
data = data.to(device)
target = target.to(device)
# Forward pass
output = model(data)
# Calcula loss
loss = loss_function(output, target)
train_total_loss += loss.item()
# Conta acertos
total_correct += correct(output, target)
# Backward pass: Backpropagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
avg_tr_loss = train_total_loss / len(train_loader)
tr_loss[epoch] = avg_tr_loss
training_accuracy = total_correct / len(train_loader.dataset) * 100
# Validation phase
model.eval() # Set the model to evaluation mode
val_total_loss = 0.0
val_total_correct = 0
with torch.no_grad():
for data, target in valid_loader:
data = data.to(device)
target = target.to(device)
# Forward pass
output = model(data)
# Calcula loss
loss = loss_function(output, target)
val_total_loss += loss.item()
# Conta acertos
val_total_correct += correct(output, target)
avg_val_loss = val_total_loss / len(valid_loader)
val_loss[epoch] = avg_val_loss
validation_accuracy = val_total_correct / len(valid_loader.dataset) * 100
tepoch.set_postfix(train_loss=avg_tr_loss, train_acc=training_accuracy, val_loss=avg_val_loss, val_acc=validation_accuracy)
tepoch.update(1)
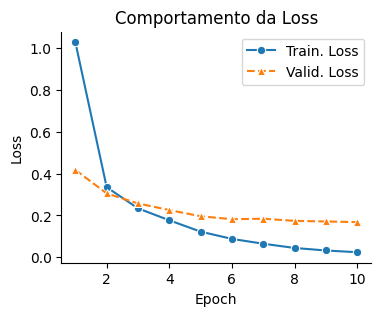
epoch_ticks = [i+1 for i in range(epochs)]
plt.figure(figsize=(4,3))
sns.lineplot(x=epoch_ticks, y=tr_loss, marker="o", label="Train. Loss" )
sns.lineplot(x=epoch_ticks, y=val_loss, marker="^", linestyle="--", label="Valid. Loss")
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title("Comportamento da Loss")
plt.legend()
sns.despine()
plt.show()
train_model_mini_batch_with_validation(
EPOCHS,
train_loader,
valid_loader,
model,
loss_function,
optimizer)
Convolução em CNNs#
|
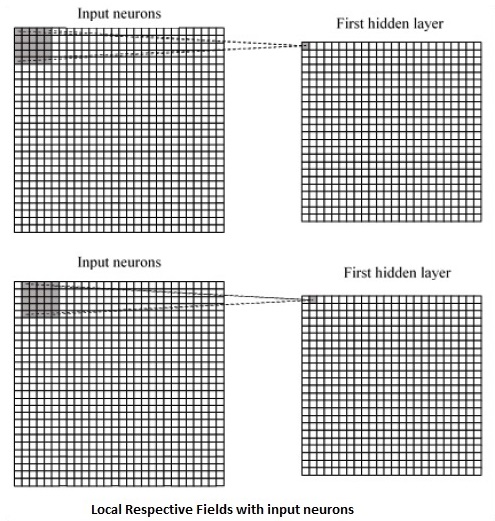 Convolução na camada escondida. Fonte: Michael Nielsen.
Convolução na camada escondida. Fonte: Michael Nielsen.
|
Convolução em CNNs#
|
Convolução no primeiro neurônio da camada escondida. Fonte: Michael Nielsen.
|
Convolução em CNNs#
A operação de convolução (para fins de CNN) é o produto escalar (multiplicação elemento a elemento seguida por soma) entre o filtro e a região de entrada correspondente. \(\text{Output} = \sum_{i, j} (\text{Input}_{i, j} \times \text{Filter}_{i, j}) + \text{Bias} \)
O resultado é um único número que mede o grau de correspondência do filtro com a região de entrada. Veja também: Convolution arithmetic.
Esse processo é repetido para cada localização onde o filtro desliza.
Os resultados são colocados em uma matriz de saída chamada Mapa de Ativação (Activation Map) ou Mapa de Características (Feature Map).
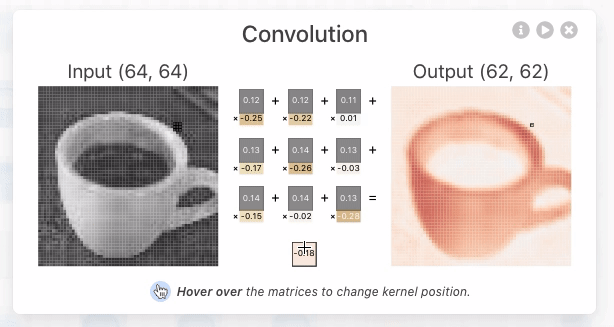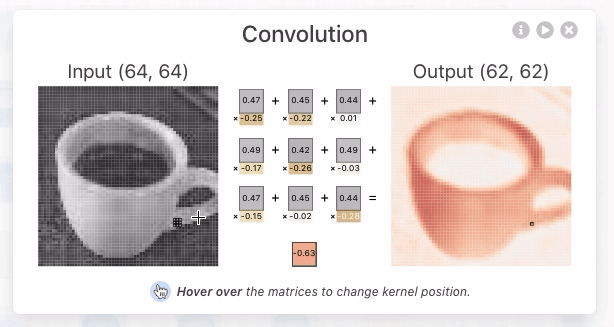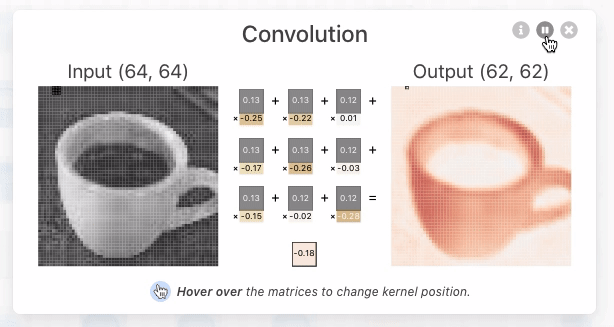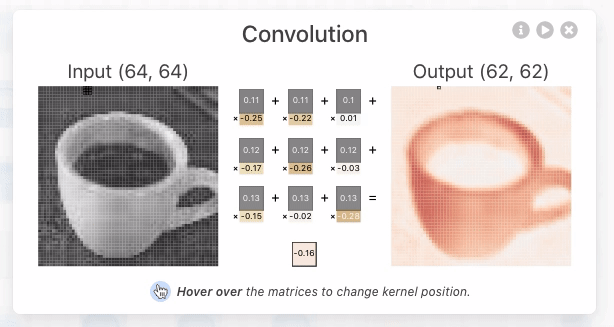
Convolução 3D#
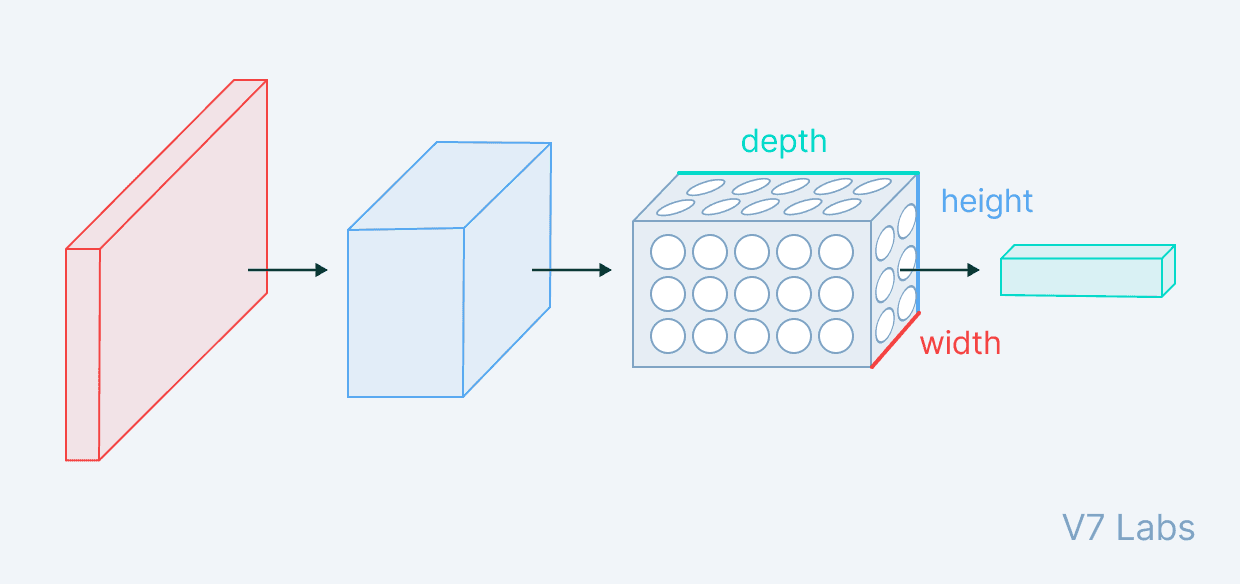
Hyperparâmetros da Convolução#
Kernel Size (\(F\)): Tamanhos comuns são \(3 \times 3\) ou \(5 \times 5\). Tamanhos menores são frequentemente preferidos para extrair features com menos parâmetros.
Número de Filtros: Aumenta com a profundidade; geralmente começa em 32 e dobra (64, 128, etc.).
Stride (\(S\)): É o número de pixels que o filtro se move (desloca) sobre a entrada a cada iteração.
Stride = 1: O filtro se move um pixel por vez, resultando em sobreposição de campos receptivos e um mapa de ativação grande.
Stride > 1: Causa um “salto” maior do filtro, resultando em menos etapas e um mapa de ativação espacialmente menor.
Um stride maior reduz a dimensionalidade e o custo computacional.
Padding: É a adição de pixels extras (geralmente com valor zero, Zero-Padding) em torno das bordas da imagem de entrada.
Problema de Redução: Sem padding, a convolução geralmente reduz o tamanho espacial da saída. Padding garante que os pixels de borda (que seriam pouco usados) participem do campo receptivo.
Padding “Same” (Igual): Adiciona zeros o suficiente para que a dimensão espacial da saída seja a mesma da entrada (assumindo \(S=1\)).
Padding “Valid” (Válido): Não usa padding, resultando em uma saída menor que a entrada.
Mapa de Ativação#
Determinando o Tamanho do Mapa de Ativação:
O tamanho espacial de saída \(O\) de uma camada convolucional é determinado pela dimensão de entrada (\(N\)), tamanho do kernel (\(F\)), Padding (\(P\)) e Stride (\(S\)).
Para que o resultado seja um inteiro, a fórmula abaixo deve ser satisfeita.
Exemplo: Imagem de entrada \(32 \times 32\) (\(N=32\)), Kernel \(5 \times 5\) (\(F=5\)).
Cenário 1 (Stride e Padding): Stride \(S=1\). Para obter Same Padding (preservar 32x32), \(P\) deve ser: \(P = (F-1)/2 = (5-1)/2 = 2\).
\(O = \frac{32 - 5 + 2(2)}{1} + 1 = \frac{31}{1} + 1 = 32\)
A saída é \(32 \times 32\) (tamanho preservado).
Cenário 2 (Sem Padding, Stride 1): \(P=0, S=1\).
\(O = \frac{32 - 5 + 0}{1} + 1 = 27 + 1 = 28 \)
A saída é \(28 \times 28\).
Compartilhamento de Parâmetros#
O Compartilhamento de Parâmetros é uma característica distintiva das CNNs.
O mesmo filtro (conjunto de pesos) é usado em todas as posições espaciais da camada de entrada.
Para um filtro 5x5: \(\sigma\left(b + \sum_{l=0}^4 \sum_{m=0}^4 w_{l,m} a_{j+l, k+m} \right)\)
Vantagem I: Redução de Parâmetros: Em vez de cada neurônio ter seu próprio conjunto de pesos, muitos neurônios compartilham o mesmo filtro.
Vantagem II: Equivariância à Translação: Se uma característica (ex: uma linha) for útil em uma parte da imagem, ela será útil em qualquer outra parte.
O filtro aprende a detectar a característica independentemente da sua localização exata.
Função de Ativação (ReLU)#
Após a operação de convolução (que é linear), uma função de ativação é aplicada ao mapa de ativação para introduzir não-linearidade.
ReLU é a função mais comum: \(f(x) = \max(0, x)\).
Ela remove valores negativos, ajustando-os para zero, o que pode ser visto como uma função de limiar (thresholding).
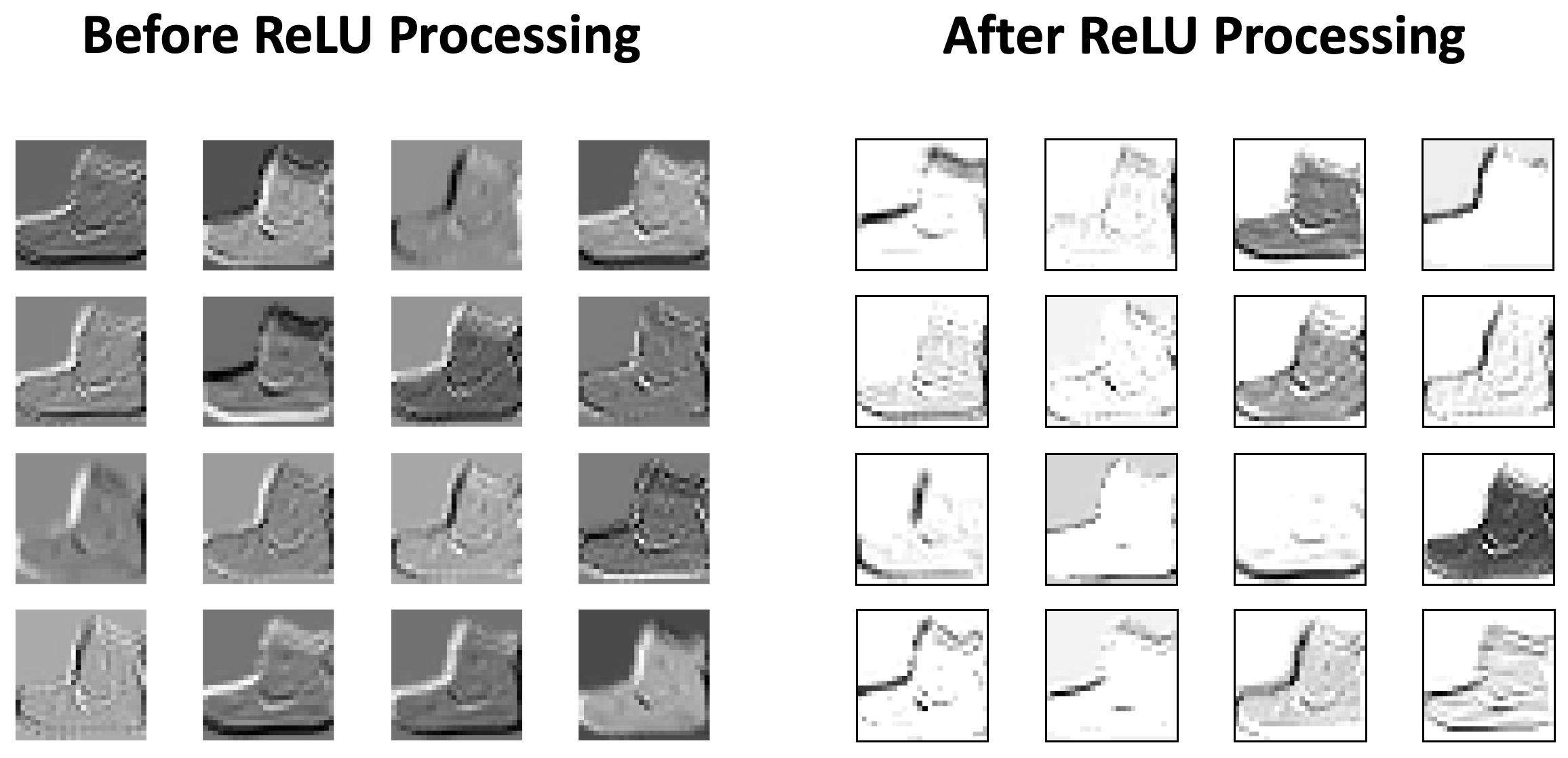
Pooling (Subamostragem)#
O Pooling é uma forma de subamostragem (downsampling) não linear, geralmente inserida periodicamente entre camadas convolucionais.
Objetivos Principais:
Reduzir a dimensionalidade espacial (Altura e Largura).
Reduzir o número de parâmetros e a quantidade de computação.
Ajudar a controlar o overfitting.
Conceder um grau de invariância local à translação.
O filtro de pooling não tem parâmetros treináveis (não tem pesos).
Um \(2 \times 2\) Max Pooling com \(S=2\) descarta 75% das ativações espaciais
 Max pooling. Fonte: Stanford.edu.
Max pooling. Fonte: Stanford.edu.
|
 Average pooling. Fonte: Stanford.edu.
Average pooling. Fonte: Stanford.edu.
|
Pooling: Exemplo numérico#

Fully Connected (FC)#
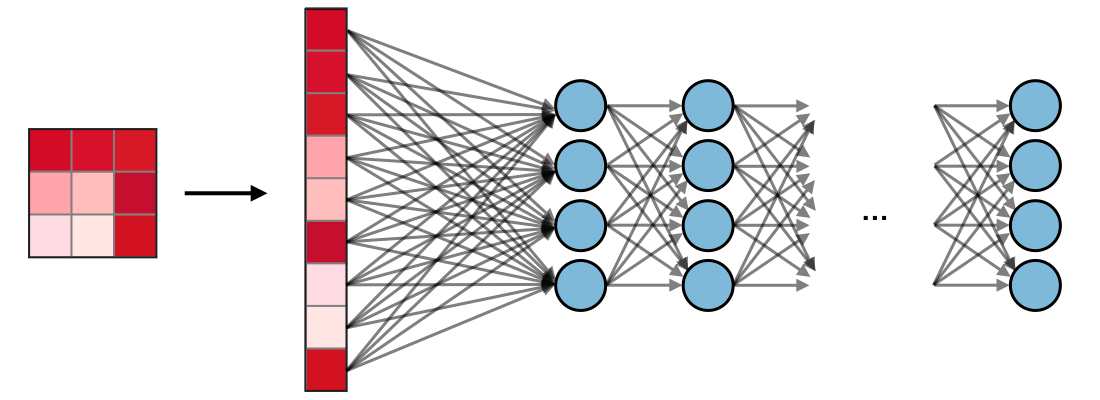
Após uma série de camadas Convolucionais e de Pooling, o volume de dados contém características de alto nível.
A última etapa é a classificação, realizada por camadas Totalmente Conectadas (FC) (ou densas).
Flattening (Achatamento): O volume 3D final do extrator de características deve ser convertido em um vetor 1D antes de entrar na primeira camada FC.
As camadas FC mapeiam as características extraídas para as probabilidades de classe.
O número de neurônios na camada de saída é igual ao número de classes (e.g., 10 para MNIST).
Para classificação de imagens: A camada de saída do classificador FC tipicamente usa a função de ativação Softmax para converter os valores brutos de saída da rede em probabilidades normalizadas.
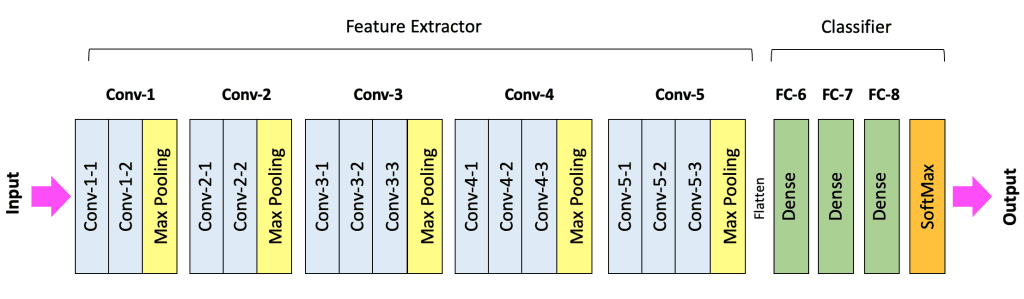
Arquitetura CNN#
Uma CNN de classificação é dividida em duas partes principais:
Extrator de Características (Feature Extractor): Composto por blocos Conv + ReLU + Pooling (ou ConvBlocks). É comum empilhar 2 ou 3 camadas Conv/ReLU consecutivas antes de uma camada Pooling.
Classificador (Classifier): Composto por camadas FC + Softmax.
O fluxo de dados transforma o volume de entrada, tipicamente reduzindo as dimensões espaciais (H, W) e aumentando a profundidade (Canais/Filtros).
Hierarquia de Características:
Camadas iniciais aprendem elementos simples (bordas, cores).
Camadas médias combinam elementos simples em formas mais complexas (e.g., olhos, rodas).
Camadas profundas aprendem conceitos abstratos de alto nível (e.g., faces, objetos inteiros).
Treinamento#
As CNNs são tipicamente treinadas usando Aprendizado Supervisionado.
Os pesos iniciais (elementos dos filtros) são definidos aleatoriamente.
O processo de aprendizagem utiliza o Backpropagation e o Gradiente Descendente.
Loss Function (Função de Perda): Mede o erro entre a previsão da rede e o rótulo verdadeiro (Ground Truth).
Otimização: O algoritmo ajusta iterativamente os pesos (filtros e FC) para minimizar a perda.
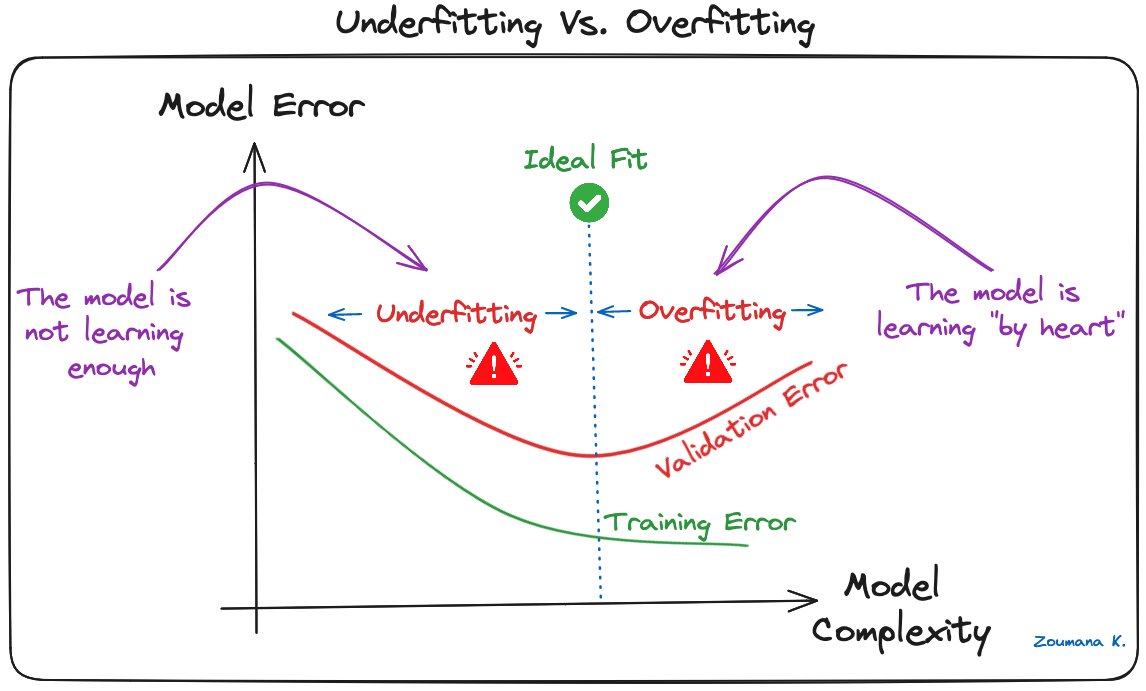
Resumo#
|
 Leitura Recomendada: Capítulo 9.
Leitura Recomendada: Capítulo 9.
|
Perguntas e Discussão#
O Perceptron Multicamadas (MLP) é a arquitetura básica de redes neurais. Por que os MLPs são inerentemente inadequados para processar imagens de alta resolução, e como a CNN supera a principal limitação de dimensionalidade do MLP?
As três principais operações em um extrator de características de CNN são Convolução, ReLU e Pooling. Qual é a contribuição fundamental de cada uma dessas operações para a capacidade de uma CNN aprender e generalizar, especialmente no contexto de downsampling?
O treinamento de uma CNN envolve o aprendizado automático de filtros (pesos). Descreva a natureza hierárquica das características aprendidas em CNNs profundas. O que um filtro (kernel) típico nas camadas iniciais detecta em comparação com as características detectadas nas camadas mais profundas?
Qual é o objetivo do Zero-Padding e qual o valor de padding (\(P\)) deve ser escolhido para um filtro de tamanho \(F\) se quisermos garantir que a saída espacial (\(O\)) seja exatamente a mesma que a entrada espacial (\(N\)), assumindo um Stride (\(S\)) de 1? Demonstre usando a fórmula do tamanho de saída.
Vimos que os filtros não são pré-definidos manualmente, mas sim aprendidos. Na fase de treinamento, como o algoritmo de Backpropagation (Retropropagação) “sabe” qual filtro deve ser ajustado para detectar uma curva ou uma linha, se os pesos são inicializados aleatoriamente? Por que esse processo não é considerado “sorte” ou aleatório?